
Basics
Definition: Let $I \subseteq \mathbb{R}$. Let $X_t : \Omega \to \mathbb{R}, t\in I$, be random variables on the same probability space $(\Omega. \mathcal{F}, P)$. Then $X = (X_t)_{t \in I}$ is called a real-valued stochastic process.
Expected value / Expectation / Erwartungswert / 期望
Definition : Let $X$ be a random variable on a probability space $(\Omega,\mathcal{F},P)$. The expectation of $X$ is defined by
Theorem: Let $X:\Omega \to S$ be a random variable on a probability space $(\Omega,\mathcal{F},P)$ with distribution $\mu$ and let $g:S\to \mathbb{R}$ be a measurable function. Then
Corollary: If $X$ is a discrete random variable with values in $S$, then
Corollary: If $X$ is a discrete random variable with values in $S \subseteq \mathbb{R}$, then
Proof: Choose $g = id_S: S \to S \subseteq \mathbb{R}$.$\square$
Corollary: If $X : \Omega \to \mathbb{R}^n$ has the probability density function (Verteilungsdichte) $f$, then for every Borel-measurable function $g : \mathbb{R}^n \to \mathbb{R}$, the following holds:
Corollary: If $X$ has values in $\mathbb{R}$
Theorem (Linearity): Let $X,Y :\Omega \to \mathbb{R}$ be random variables in $\mathcal{L}^1$. Then
Theorem: Let$X,Y :\Omega \to \mathbb{R}$be independent random variables, $g,h: \mathbb{R} \to \mathbb{R}$ be Borel-measurable function with $E[|g(X)|], E[|h(Y)|] < \infty$. Then
proof: Since $X$ and $Y$ are independent, the joint distribution of $(X, Y)$ is the product of the marginal distributions $P_X \times P_Y$. Using Fubini’s theorem, we obtain
$\square$
Corollary: Let$X,Y :\Omega \to \mathbb{R}$be independent random variables in $\mathcal{L}^1$, then
Moment
Definition : $E[X^n]$is called the $n^{\text{th}}$ moment of X.
Theorem:
Let $X \sim \mathcal{N}(\mu,\sigma^2)$ be a random variable. Then for any non-negative integer $p$ we have:
Here, $n!!$ denotes the double factorial, that is, the product of all numbers from $n$ to 1 that have the same parity as $n$.
Corollary:
Let $X \sim \mathcal{N}(0,\sigma^2)$ be a random variable. Then for any non-negative integer $p$ we have:
Example:
Let $X \sim \mathcal{N}(0,\sigma^2)$ be a random variable, we have:
- $\mathbb{E}[X^2] = \sigma^2$
- $\mathbb{E}[X^3] = 0$
- $\mathbb{E}[X^4] = 3 \sigma^4$
Variance / Varianz / 方差
Definition: Let$X\in \mathcal{L}^1$. Then
is called the variance of$X$and
is the standard deviation of $X$.
Theorem: Let$X\in \mathcal{L}^1$, then
proof:
let $\mu:=E[X]$.
$\square$
Theorem: Let $X$ be a random variable with finite expectation. For $a,b \in \mathbb{R}$, it holds that:
proof:
$\square$
Theorem: Let $X,Y$ be independent random variables, then
proof:
$\square$
Theorem:
Let $X,Y$ be independent random variables, then
Proof:
. $\square$
Covariance / 协方差
Definition :For real-valued random variables$X, Y \in L^2$, the covariance of$X$and$Y$is defined by
Theorem:
(a) $\text{Cov}(X, X) = \text{Var}(X)$
(b) $\text{Cov}(X, Y) = \mathbb{E}[XY] - \mathbb{E}[X]\mathbb{E}[Y]$
(c) If $X$ and $Y$ are independent, then $\operatorname{Cov}(X, Y) = 0$.
Proof:
(a) Clear from the definition.
(b) By the linearity of expectation, it follows:
(c) The claim follows from $\mathbb{E}[XY] = \mathbb{E}[X]\mathbb{E}[Y]$.$\square$
Theorem: Let $X_i, Y_j \in L^2$, $a_i, b_j \in \mathbb{R}$, $1 \leq i \leq n$, $1 \leq j \leq m$. Then:
(a) The covariance is bilinear:
(b)
In particular:
(c) If $X_1, \dots, X_n$ are uncorrelated, i.e., $\operatorname{Cov}(X_i, X_j) = 0$ for all $i \neq j$, then:
This holds especially if $X_1, \dots, X_n$ are independent.
Proof:
(a) Since $\operatorname{Cov}(X, Y) = \operatorname{Cov}(Y, X)$, it suffices to show linearity in the first argument. From the linearity of expectation, it follows:
(b) Using part (a), we get:
In the special case $n = 2$, this gives:
(c) Follows from part (b).$\square$
Moment generating function
Definition: Let $X$ be a random variable such that $\mathbb{E}[e^{tX}] < \infty$, then the moment generating function is defined as
for all $t \in \mathbb{R}$.
Theorem: Let $X \sim N(\mu,\sigma^2)$, then the moment generating function exists and is equal to
Clearly, if $X \sim N(0,1)$, we have
Proof:
Let $X \sim N(\mu,\sigma^2)$, and
be its density function. Then, by definition we have
Notice that
Then we have
p.s.: the calculation/proof of Gaussian integral
can be found here:
.$\square$
Important Inequalities
Theorem (Jensen's Inequality):
Let $\varphi:\mathbb{R} \to \mathbb{R}$ be convex. If $\mathbb{E}[|X|] < \infty$, then $\mathbb{E}[\varphi(X)]$ is well-defined and one has
Corollary:
1.
2. for $p \geq 1 :$
3. for $1 \leq p < q :$
proof:
1. take $\varphi(x) = |x|$.
2. take $\varphi(x) = |x|^p, p \geq 1$.
3. Let $1 \leq p < q , \alpha := q/p > 1, Z := |X|^p$. From 2 we have
$\square$
Theorem (Markov's inequality):
Let $X$ be a real-valued random variable and let $f : [0, \infty) \to [0, \infty)$ be a monotonically increasing function with $f(x) > 0$ for all $x > 0$.
Then for all $a > 0$ we have:
In particular, for all $a, p > 0$, it holds:
Proof:
Since $f \geq 0$ and is monotonically increasing, we have :
From the monotonicity of the expectation, it follows that:
Since $f(a) > 0$, the claim follows. $\square$
Theorem (Chebyshev's inequality):
Let $X \in \mathcal{L}^2$ (i.e.$\mathbb{E}[|X|^2] < \infty$) be a real-valued random variable, then for all $a > 0$ we have:
Proof:
Let $Y = X-\mathbb{E}[X]$, $f(x):=x^2$. By applying Markov’s inequality we have:
$\square$
Convergence
Definition: For $p \geq 1$ we say $Y \in L^p$ if $E[|Y|^p] < \infty$.
Definition: Let $X,X_i,i \geq 1$ be random variables on the same probability space $(\Omega,\mathcal{F},P)$.
1. $X_n \rightarrow X$ almost surely (a.s.) if
We write $X_n \xrightarrow{P-a.s.} X$.
2. $X_n \rightarrow X$ in probability if
We write $X_n \xrightarrow{P} X$ or $X_n \xrightarrow{\text{in probability}} X$.
3. $X_n \to X$ in $L^p$ for $p \geq 1$ if $X_n \in L^p$ for all $n$, $X \in L^p$, and
We write $X_n \xrightarrow{L^p} X$.
Definition: Let $\mu_n, \mu$ be probability measures on $(\mathbb{R}, \mathcal{B}(\mathbb{R}))$, we say that $\mu_n$ converges weakly to $\mu$ ($\mu_n \Rightarrow \mu$ or $\mu_n \xrightarrow{w} \mu$) if
We say $X_n \xrightarrow{w} X$ if $\mathcal{L}(X_n) \xrightarrow{w} \mathcal{L}(X)$, where $\mathcal{L}(X_n)$ denotes the distribution of $X_n$.
Remark:
Proof: $E[f(Y)] = \int f(y) \, \mu(dy) \quad \text{with } \mu = \mathcal{L}(Y).$$\square$
Theorem:
(a) If $p_1 < p_2$, then $X_n \to X$ in $L^{p_2}$ implies $X_n \to X$ in $L^{p_1}$.
(b) $X_n \to X$ in $L^p$ or almost surely implies $X_n \to X$ in probability.
(c) Suppose there exists $Y \in L^p$ such that $|X_n| \leq Y$ for all $n$. If $X_n \to X$ in probability and $X \in L^p$, then $X_n \to X$ in $L^p$.
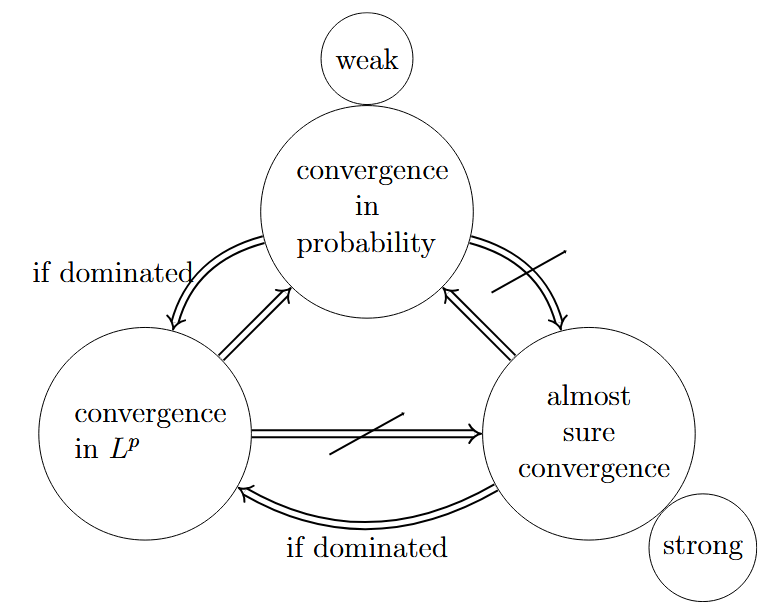
proof:
$\square$
Corollary: If $X_n \to X’$ in $L^p$ and $X_n \to X’’$ almost surely, then $X’ = X’’$ a.e. (i.e. $P(X’ = X’’) = 1$).
proof:
It follows from the Theorem that $X_n \to X$ and $X_n \to X’’$ in probability, since the limit is unique, one has $X’ = X’’$ a.e.$\square$
Conditional Expectation
Definitions
Definition:
Let $(\Omega, \mathcal{F}_0, P)$ be a probability space. Let $X : \Omega \to [-\infty, +\infty]$ be an $(\mathcal{F}_0, \mathcal{B}([-\infty,+\infty]))$-measurable random variable with $\mathbb{E}[|X|] < \infty$ or $X \geq 0$, and let $\mathcal{F} \subseteq \mathcal{F}_0$ be a $\sigma$-algebra.
The conditional expectation $\mathbb{E}[X \mid \mathcal{F}]$ of $X$ given $\mathcal{F}$ is a random variable $Y : \Omega \to [-\infty, +\infty]$ with the following properties:
(C1) $Y$ is $(\mathcal{F}, \mathcal{B}([-\infty,+\infty]))$-measurable.
(C2)
If $\mathbb{E}[|X|] < \infty$, then $\mathbb{E}[X \mid \mathcal{F}]$ is almost surely finite. Every random variable fulfilling (C1) and (C2) is called a version of $\mathbb{E}[X \mid \mathcal{F}]$.
Definition:
Theorem:
The conditional expectation exists and is almost surely unique.
Proporties
Theorem:
1. $X$ $\mathcal{F}$-measurable $\Longrightarrow$ $\mathbb{E}[X\mid \mathcal{F}] = X$ almost surely.
2. $\sigma(X)$ and $\mathcal{F}$ are independent $\Longrightarrow$ $\mathbb{E}[X \mid \mathcal{F}] = \mathbb{E}[X]$ almost surely.
Theorem:
1. Linearity: For $a \in \mathbb{R}$,
2. Monotonicity: $X \leq Y \quad \Longrightarrow \quad \mathbb{E}[X \mid \mathcal{F}] \leq \mathbb{E}[Y \mid \mathcal{F}]$ almost surely.
3. Monotone convergence: $X_n \geq 0$, $X_n \uparrow X \quad \Longrightarrow \quad \mathbb{E}[X_n \mid \mathcal{F}] \uparrow \mathbb{E}[X \mid \mathcal{F}]$ almost surely.
Theorem:
Theorem:
If $X$ is $\mathcal{F}$-measurable, $\mathbb{E}[|XY|] < \infty$ and $\mathbb{E}[|Y|] < \infty$, then
This holds also if $X \geq 0$ and $Y \geq 0$.
Theorem (“The smaller $\sigma$-algebra wins”) : Let $\mathcal{F}_1, \mathcal{F}_2$ be $\sigma$-algebras satisfying $\mathcal{F}_1 \subseteq \mathcal{F}_2$,$X$ be random variable. Then
almost surely.