
本篇文章主要介绍x86-64架构的64位程序下的pwn漏洞以及利用思路。
(很多背景知识,安全性检查以及介绍工具功能的内容可能一开始完全看不懂,但是可以不用太在意。先知道有这么个东西,在后面看到需要相关知识/命令的时候再回来看就好。)
背景知识
地址空间(Address space,Prozess Adressraum)
地址空间可以被看作是一个巨大的 一维字节数组,在程序运行时(与它潜在的大小相比),其中只有少数位置存有数据。由于地址空间占用非常稀疏,操作系统会将其划分为大小相等的 页(Pages),其中只有被操作系统释放(映射)的页才可以被访问。
程序从硬盘被加载到低地址空间(对应的页由操作系统或程序加载器自动提供)。
用于执行的机器代码存放在 文本段(Text Segment) 中,静态初始化的变量和字符串常量存放在 数据段(Data Segment) 中。静态变量如果在程序开始时尚未被赋值,则会放在 BSS 段 中,并由操作系统填充为零字节。
程序所需的动态链接库也由这三类段组成,并由程序加载器加载到更高的内存地址。由于这些库所需的内存是通过 mmap 系统调用 向操作系统申请的,因此它们也被称为 MMap 段。
在程序初始化过程中,还会额外保留两个区域:
- 栈(Stack):用于自动管理的变量。
- 堆(Heap):用于动态分配的变量。
栈在每次函数调用时会扩展一个 栈帧(Stack Frame)。在栈帧的内存区域中存储有当前函数的局部变量,以及一些管理信息,例如 返回地址。返回地址记录了当前执行的函数是从哪一个程序地址被调用的。随着函数调用深度的增加,栈会从高地址向低地址方向增长。
当需要在函数执行完毕后变量仍然存在时,就必须使用堆来进行动态内存分配(因为栈上的变量会在函数返回时自动释放)。在这种情况下,程序可以通过libc 提供的分配器使用malloc函数向系统申请内存。如果可能,分配器会返回对程序启动时预留的堆区域的引用;如果堆空间不足,分配器会通过 mmap 系统调用 向操作系统请求一个新的 MMap 段,并返回对该段的引用。
C 标准库(libc)除了包含内存分配器之外,还提供了许多常用函数,以便简化与操作系统的交互。
代码(文本段)是静止的,但动态库(libc)的地址每次运行时可能都会变(ASLR),或者在程序写好时根本不知道它在哪里。那程序是如何找到printf或system的真实地址的呢?
这个时候就需要PLT和GOT了:
- PLT (Procedure Linkage Table - 过程链接表):
- 存放在.plt 段(类似于文本段,是只读、可执行的代码)。
- 指向GOT(记录的函数的GOT地址)
- GOT (Global Offset Table - 全局偏移表):
- 存放在.got.plt 段(属于数据段的一部分,是可读、可写的数据)。
- 初始时指向PLT,解析后指向libc
Linux 为了启动速度,默认不会一开始就把所有函数的地址都填好,而是真正用到的时候才去找实际地址。这个过程叫延迟绑定。
延迟绑定主要分为2种过程:
过程一:首次调用(符号解析阶段)
当程序第一次尝试调用共享库中的函数(如 printf)时,由于地址尚未解析,执行流程如下:
- 调用 PLT 存根 (Call PLT Stub) 程序
.text段执行call printf@plt指令,将控制流转移至.plt段中对应的printf存根代码。 - 间接跳转 (Indirect Jump) PLT 存根执行第一条指令
jmp *printf@GOT。这是一条间接跳转指令,目标地址从全局偏移表(.got.plt)的对应条目中读取。 - 回落至 PLT (Fallthrough) 在初始化状态下,
.got.plt中存储的地址并非函数的真实地址,而是 PLT 存根中下一条指令的地址(即紧随上述jmp指令之后的地址)。因此,执行流并未跳转至外部,而是继续执行 PLT 存根中的剩余代码。 - 准备重定位参数 (Prepare Relocation) PLT 存根将该符号在重定位表中的索引(Relocation Index)压入栈中,随后跳转至 PLT 的公共头部(PLT[0])。
- 调用动态链接器 (Invoke Dynamic Linker) PLT[0] 将链接映射结构(link_map)压入栈,并调用动态链接器的解析函数(通常为
_dl_runtime_resolve)。 - 符号解析与地址回填 (Resolution & Patching)
_dl_runtime_resolve遍历依赖库的导出符号表,查找printf的实际虚拟地址(例如0x7ffff7a0d123)。找到后,它执行两个操作:- 执行函数:调用目标函数。
- 更新 GOT:将查找到的真实地址写入
.got.plt中对应的条目,覆盖原有的回落地址。
过程二:后续调用(直接执行阶段)
当程序再次执行 call printf@plt 时,由于 GOT 表项已被更新,流程简化如下:
- 调用 PLT 存根 (Call PLT Stub) 程序再次执行
call printf@plt,跳转至.plt段。 - 间接跳转至目标 (Direct Redirection) PLT 存根再次执行
jmp *printf@GOT。此时,系统从.got.plt中读取到的已是printf的真实地址(0x7ffff7a0d123)。 - 控制流转移 (Control Transfer) CPU 直接跳转至共享库中的
printf函数入口执行,不再触发动态链接器的解析过程。
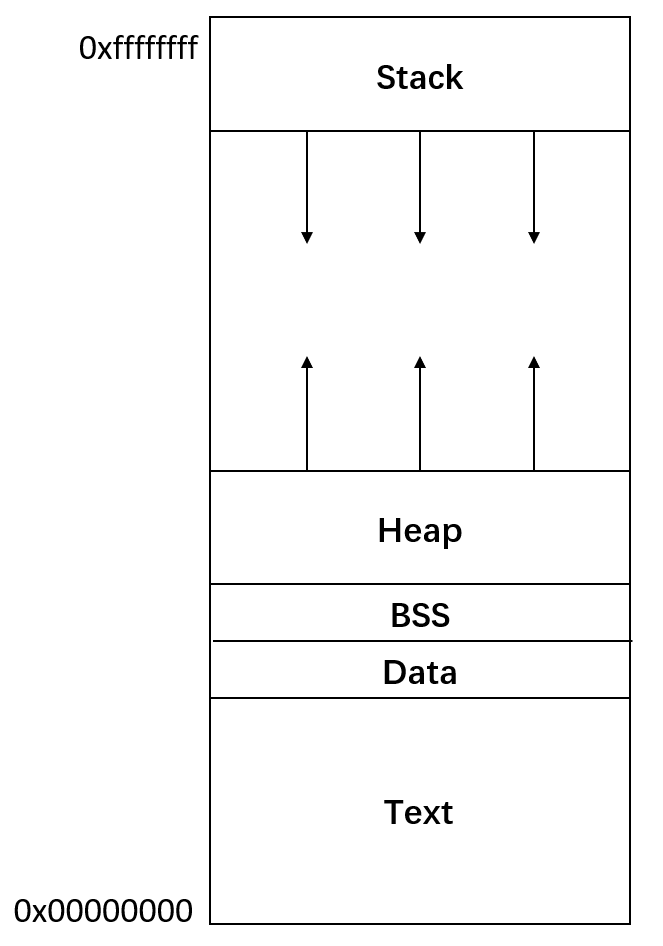
更详细的地址空间结构图示:
1 | 高地址 (High Address) (通常是 0x7fffffffffff) |
如果开启了ASLR(下面会讲),那么Stack Base (栈基址)、MMap Base (映射区基址)、Heap Base (堆基址)在每次程序运行的时候都是随机的地址。
在程序执行过程中,如果访问了一个无效的地址(即未映射的页),操作系统会向程序发送一个 段错误(Segmentation Fault) 信号。如果程序没有对此进行处理,就会导致程序终止。
X86汇编
因为汇编设计的内容太多了,这里没法全都讲,所以大家自己找点其他的资料学一学。
但是并不是说不懂汇编就完全没法做和理解pwn题,所以也可以边学pwn边学汇编,这样有实际例子的情况下也可用更好更高效地掌握汇编。
下面主要提一些比较重要的点:
Linux x64(System V AMD64 ABI)传参顺序:
RDI(第 1 参数)。RSI(第 2 参数)RDX(第 3 参数)RCX(第 4 参数)R8(第 5 参数)R9(第 6 参数)- 后续的参数会被存在栈上
其他的常用寄存器:
- RIP (Instruction Pointer)
- 定义:指向下一条要执行的指令地址。
- PWN意义:当函数执行
ret时,CPU 会把那个地址弹给 RIP。
- RSP (Stack Pointer)
- 定义:永远指向栈顶。
- PWN意义:
push和pop都会自动修改它。
- RBP (Base Pointer)
- 定义:栈帧的基址(底)。
- PWN意义:主要用于定位局部变量。配合
leave; ret可以实现栈迁移。
- RAX (Accumulator)
- 常规用途:算术运算结果、函数的返回值。
- PWN核心用途 (Syscall): 在做ret2Syscall/SROP(利用系统调用拿 shell)时,
RAX决定了要呼叫内核做什么。RAX = 59(0x3b) -> 对应execve系统调用(运行程序)。RAX = 0->readRAX = 1->writeRAX = 15->rt_sigreturn
- 特殊段寄存器:FS (Segment Register)
- PWN意义:在64位Linux下,Canary的值总是存在
fs:[0x28]这个位置。
- PWN意义:在64位Linux下,Canary的值总是存在
Gadget
Gadget是指由于代码复用攻击(Code Reuse Attack)需求,而在现有的可执行内存段(如 .text 段或共享库)中被分离出来的、以控制流转移指令(Control Transfer Instruction)结尾的一段机器指令序列。
最常见的形式是ROP Gadget(Return-Oriented Programming Gadget),其结尾指令严格为ret (Return)。
一个标准的 Gadget 由两部分组成:
- 操作指令序列 (Operational Instructions):执行实际的计算、数据传输或逻辑运算(如
pop,mov,add,xor)。 - 终结指令 (Terminator):用于将控制权交还给攻击者控制的机制。在 ROP 中,这是
ret指令。
执行原语: Gadget 并不像正常函数那样通过 call 调用,而是通过栈指针(RSP/ESP)作为伪指令指针来驱动。
ret的本质:pop rip。它从栈顶弹出一个值赋给 RIP(指令指针)。- 攻击者在栈上预先布置好一连串的地址(ROP Chain)。
- 每一个 Gadget 执行完其逻辑后,执行
ret,这会导致 CPU 从栈上读取下一个 Gadget 的地址并跳转执行。
这种机制使得 RSP 实际上替代了 RIP 的角色,而栈上的数据流变成了指令流。
常用的gadget:
pop rdi ; ret、pop rsi ; ret、pop rdx ; ret:设置函数的参数pop rbp:把栈顶的8字节弹到寄存器rbp,同时rsp += 8。
安全性检查
我们可以使用checksec命令检查一份二进制文件的安全性.
安装:
1 | sudo apt install checksec |
例子:
1 | └─$ checksec ./vuln |
1 | └─$ checksec ./racecar |
1 | └─$ checksec vuln |
1 | └─$ checksec vuln |
解释:
Arch:二进制文件的架构amd64-64-little: x86-64架构的64位小端序ELF可执行文件;i386-32-little:x86架构的32位小端序ELF可执行文件
NX:Non-eXecutable,表示数据段不可执行。disabled / Stack: Executable:可以直接在栈/堆执行shellcode;enabled:栈和堆不能直接执行代码。
PIE:Position Independent Executable,表示主程序不依赖于固定的绝对内存地址,而是能够被加载到任意基址,即main、.text、.data、.bss等的运行时实际地址会变成基址+绝对内存地址(base_addr + offset)的形式。在系统开启 ASLR 时,每次运行主程序会选择不同的基址。No PIE:程序总是加载在固定的绝对内存地址;也就是说我们用工具读取到的如
.bss的地址和程序实际运行时.bss的地址是有一样的。PIE enabled:主程序基址随机化。我们用工具读取到的如
.bss的地址和程序实际运行时.bss的地址是有不一样的,实际地址会等于我们读取到的地址加上一个随机的基址base_addr。
RELRO:Read-Only Relocations,程序启动时完成必要的重定位后,把用于重定位相关的数据区(尤其是 GOT 等)所在的内存页改成只读。Full RELRO:.got,.got.plt完全只读;Partial RELRO:只部分保护,.got只读,但.got.plt仍可以修改;No RELRO:完全没有保护,.got,.got.plt均可修改。
Stack:是否启用了栈金丝雀(Stack Canary):一种用于检测栈缓冲区溢出的运行时保护机制。编译器在函数的栈帧中、局部变量与返回地址之间插入一个随机(或带固定格式)的“金丝雀值”;函数返回前会检查该值是否被改写。若发生变化,说明栈上出现了越界写(很可能覆盖到返回地址),程序会立即终止或触发安全处理。No canary found:没有栈金丝雀;Canary found:设置了栈金丝雀。
Stripped:是否剥离了符号信息。No:包含函数名、符号,方便调试和逆向分析;Yes:已剥离,更难逆向,但对运行安全性影响不大。
Debuginfo:是否带有调试信息(DWARF 等)。No:一般发布版本应去掉;Yes:含源码级调试信息,方便开发调试,但可能泄露过多信息。
除此之外,还有一个大部分机器/题目环境默认开启的保护措施:ASLR(Address Space Layout Randomization,地址空间布局随机化)。
这一种由操作系统实现的内存保护机制。在程序每次启动时,操作系统会把进程地址空间中的关键区域的基址随机化(例如栈、堆、共享库映射区(其中包括libc)、vdso 等),使代码和数据的实际地址在不同运行之间不可预测。
工具
了解一下常用的基础工具,可以先安装好,但是具体操作可以先不用管,了解了后面的漏洞以及利用方法之后再回来看/查找命令即可。
GDB
GDB(GNU Debugger)是 GNU 项目的调试器,主要用于调试 C/C++ 等程序。
安装
1 | sudo apt install gdb |
安装Pwndbg
pwndbg 是 GDB 的调试插件,提供栈/堆/寄存器上下文展示以及 cyclic、rop、heap、format 等命令,用于更高效地调试二进制漏洞。
安装:
1 | # 1) 依赖 |
安装前:
安装后:
常用命令
1. 使用GDB打开二进制文件
1 | gdb ./vuln |
-q:quiet,安静模式,不显示启动欢迎信息。
或者是先普通打开gdb,然后再选择文件:
1 | gdb |
2. 运行程序
1 | run |
3. 查看汇编代码
1 | disassemble main |
4. 设置断点
1 | break main # 在 main 函数处断点 |
5. 查看寄存器
1 | info registers |
6. 搜索gadgets
1 | rop --grep "ret" |
确定返回地址偏移
1 | pwndbg> | cyclic 1200 | tee /tmp/pat > /dev/null |
| cyclic 1200 | tee /tmp/pat > /dev/null:生成模式串并保存到文件cyclic 1200:让 pwndbg 生成长度为 1200 字节的 De Bruijn 模式串(也叫“花指纹/模式串”)。它的特性是:任意连续的 n 字节子串在整段里唯一(默认 n=4)。长这样:1
2pwndbg> | cyclic 200 | tee /tmp/pat
aaaaaaaabaaaaaaacaaaaaaadaaaaaaaeaaaaaaafaaaaaaagaaaaaaahaaaaaaaiaaaaaaajaaaaaaakaaaaaaalaaaaaaamaaaaaaanaaaaaaaoaaaaaaapaaaaaaaqaaaaaaaraaaaaaasaaaaaaataaaaaaauaaaaaaavaaaaaaawaaaaaaaxaaaaaaayaaaaaaatee /tmp/pat:写入文件/tmp/pat。> /dev/null:隐藏输出。
x/gx $rsp:读取“将要被 ret 弹到 RIP”的 8 字节x(examine):查看内存。/gx:一次显示 1 个 8 字节(g=8 bytes,“giant word”)并用 十六进制(x)格式。$rsp:取 RSP 寄存器 作为要查看的内存地址。
cyclic -n 8 -o 0x...:用得到的返回地址反推偏移-o(offset):告诉cyclic“这就是我在栈上读到的那 8 个字节”,请帮我算“它在刚才那段模式串里的起始位置(偏移)”。-n 8:在 64 位上我们读的是 8 字节(gx),要用 8 字节粒度的唯一性去匹配;否则默认 n=4 可能匹配失败或给错结果。0x...:把上一步x/gx $rsp看到的 十六进制数原样填进来。
输出:一个十进制数字,比如 Found at offset 18 —— 这就是覆盖到返回地址的偏移(字节数)。
例子
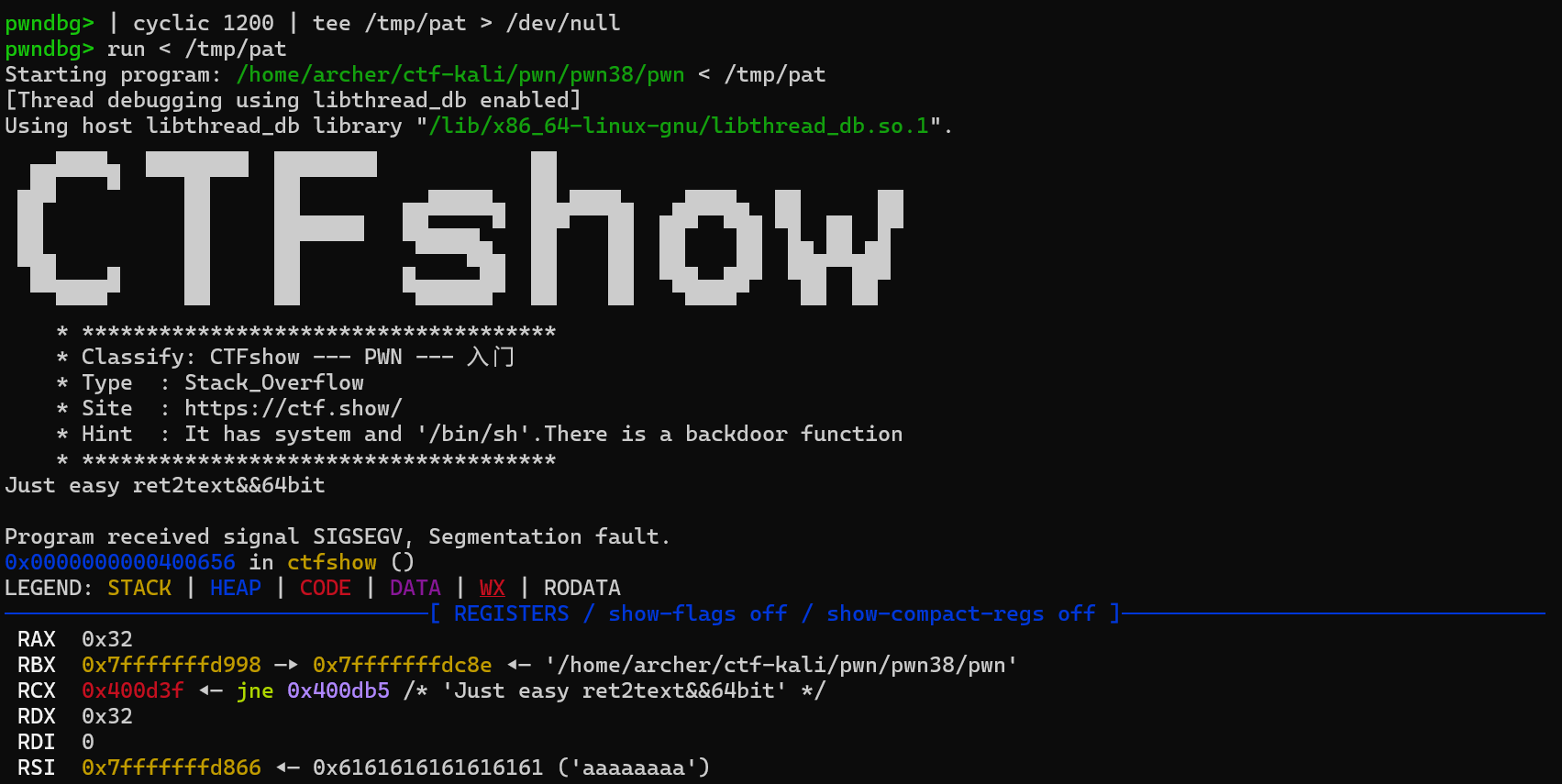
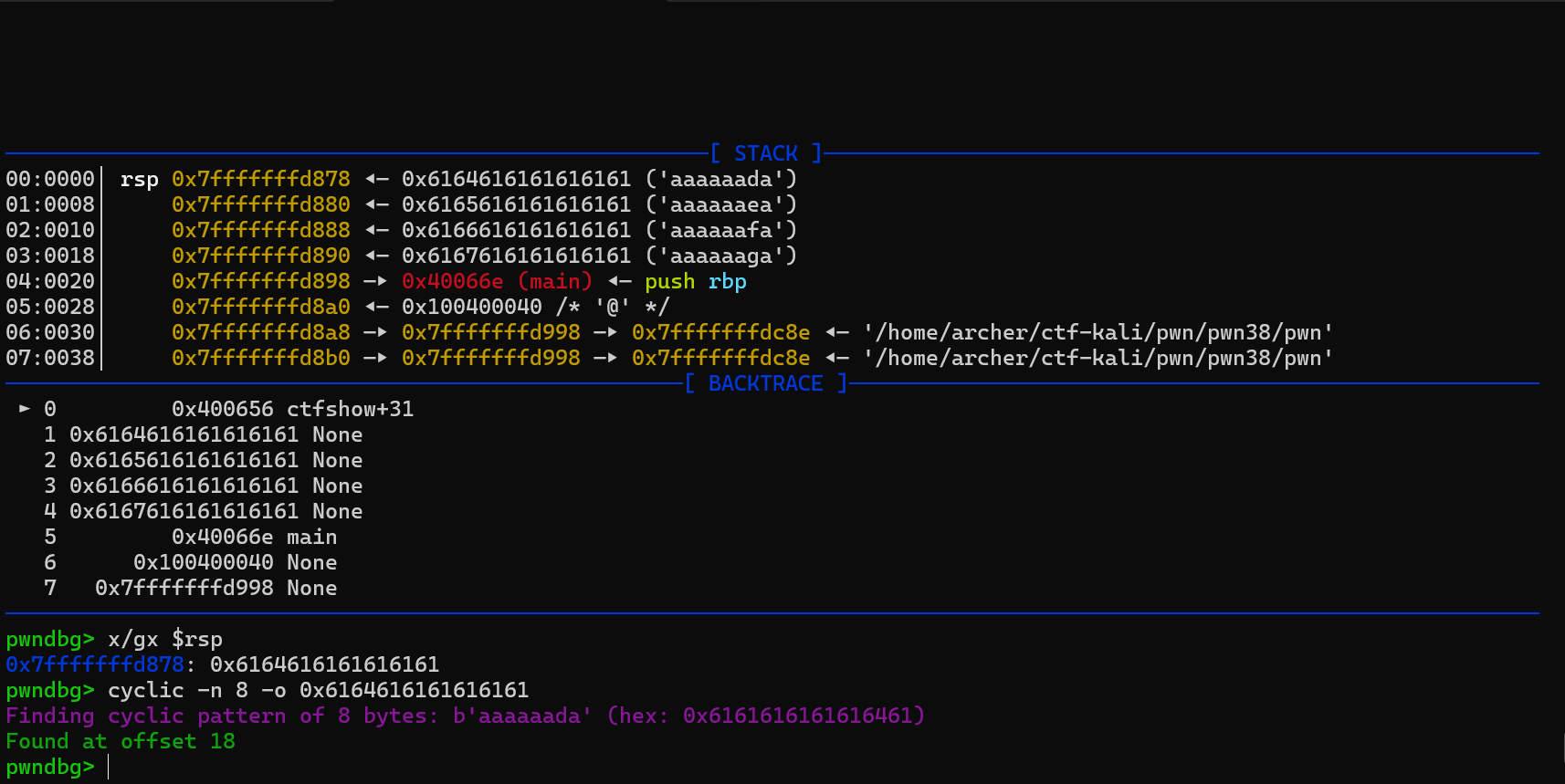
1 | pwndbg> | cyclic 1200 | tee /tmp/pat > /dev/null |
所以偏移为18。
IDA/Ghidra
很多时候题目只会给编译好的二进制程序,并不会给源代码。这个时候就需要用软件进行反编译以便查看伪代码。这样就不用死磕纯汇编语言了。
下载:
IDA免费版:https://hex-rays.com/ida-free
IDA的Pro正式版收费非常贵。所以也可以考虑用完全免费开源的Ghidra。
Ghidra:https://ghidralite.com/
Pwntools
Pwntools 是面向CTF/Pwn场景的Python库,提供连接服务、构造 payload、地址与数据的打包/解包、gadget 检索、shellcode 汇编以及 GDB 调试等功能,用于高效编写与调试利用代码(exploit)。
安装
1 | pip3 install pwntools -U |
常用 API(按任务分类)
1) 连接与交互
- (假设
io=)process(path)/remote(host, port):本地测试/远程连接 io.send(data)/io.sendline(data):发送数据/行io.recv(n)/io.recvline()/io.recvuntil(delim):接收io.sendafter(delim, data)/io.sendlineafter(delim, data):等提示再发(菜单题常用)io.clean(timeout=0.1):清空缓冲垃圾输出io.interactive():拿到交互式 shell,类似于nc。切换至这个模式时会自动print当前所有缓冲数据。
2) 打包/解包与快捷拼接
p32(x) / p64(x),u32(b) / u64(b):整型与字节序互转(小端)flat(*args, filler=b'A', length=None):会把传入的各类对象智能转换成一段字节串。它会根据context(架构/字节序/位宽)自动处理对齐与打包。例子:
1
2
3
4
5
6
7
8
9payload = flat({
0: shellcode, # shellcode
256: JMP_RSI_Adress
})
payload = flat({
0: b"A"*84,
84: win_Adress
})fit({offset: data, ...}, filler=b'A'):按偏移放置数据cyclic(n)/cyclic_find(value, n=4/8):花指纹与偏移定位(也可用 pwndbg 的)
3) 程序信息与 ROP 工具
ELF(path):读符号、plt/got、段地址等elf.symbols[]:从符号表读取符号(函数/全局变量)的地址。返回int。比如说:1
main = elf.symbols['main'] # main 函数入口
elf.search():在可执行文件已映射的各段中按字节序列搜索内容并返回一个生成器(迭代得到每个匹配的地址)。常配合next(...)取第一个匹配。。比如说1
2
3elf.search(b'/bin/sh') # 查找'/bin/sh'字符串
pop_rdi = next(elf.search(asm('pop rdi ; ret'))) # 查找'pop rdi ; ret'命令elf.got[]:获取 GOT 表项地址(存放真实函数地址的指针位置)。返回int(可写段;Full RELRO 下只读)。比如说1
got_puts = elf.got['puts'] # 取 puts 的 GOT 表项地址(&puts@GOT)
elf.plt['puts']:获取 PLT 跳板(桩函数)的地址。返回int。比如说:1
plt_puts = elf.plt['puts'] # 调用 puts@plt,把某地址当作参数打印
ROP(elf):自动搜 gadget/拼 ROProp.find_gadget(['pop rdi', 'ret']),rop.call('puts', [addr]),rop.chain()
context.binary = elf:让 pwntools 自动跟随架构
4) Shellcode / 汇编
asm('mov rax, 60; xor rdi, rdi; syscall'):将汇编转为机器码shellcraft.sh()/asm(shellcraft.sh()):/bin/sh的Shellcode。disasm(b'\x90\x90\xcc'):反汇编字节流
5) 调试辅助
gdb.attach(io, gdbscript='b *0x401234\nc'):本地挂 gdbgdb.debug([path], gdbscript=...):由 gdb 启动进程(便于断点)
6) 杂项
hexdump(data):十六进制打印log.info()/success()/warning():美化日志context.timeout = 2:全局超时pause():脚本暂停,手动操作后继续
模板
process用于本地测试,地址给二进制文件的地址;remote用于连接服务器。
1 | from pwn import * |
Ropgadget
用于高效准确查找gadgets。
下载:
1 | sudo apt install python3-ropgadget |
用法:
1 | ROPgadget --binary ./vuln | grep -E "pop rdi ; ret" |
漏洞以及利用方法
一般pwn题的核心漏洞主要分为2种:(概况地比较笼统)
- 不安全的输入/边界处理(从而导致溢出,格式化字符串漏洞等问题)
- 状态/权限/生命周期等逻辑设计或实现错误(比如最普通的Use-After_Free)
我们需要利用这些漏洞来修改程序的执行流程,从而达到读取flag或者拿到shell的目的。
下面主要分成3部分来讲:
- 溢出(主要关注栈溢出)
- 格式化字符串漏洞
- 堆利用
溢出 Buffer Overflow
Buffer overflow(缓冲区溢出)漏洞常见于不做边界检查或边界检查错误的输入/拷贝函数;可覆盖栈/堆/静态区中的相邻数据(如返回地址、函数指针、对象元数据等)。
当然初次之外还有很多溢出的漏洞表现,比如说整数溢出导致的越界写入等。
而如果溢出是发生在栈上的话,称为栈溢出。常见的利用方法是通过溢出修改栈中相邻的内容,如返回地址等。
(栈溢出的定义:指的是程序向栈中某个变量中写入的字节数超过了这个变量本身所申请的字节数,因而导致与其相邻的栈中的变量的值被改变。)
比较简单常见的栈溢出的例子的就是,程序给某个变量在栈上分配了一个固定大小的内存,但是程度接收输入时没有仔细检查,导致我们可以将超过这个内存大小的内容写入进这个变量,于是它会覆盖其更高地址的内容。
漏洞/常见危险函数
gets()- 没有任何输入长度限制/检查。
fgets(buf, size, stdin)如果
size大于给buf的实际大小,则会溢出。1
2char buf[32];
fgets(buf, 128, stdin);
scanf("%s", buf)%s会不断读入字符直到遇到空白符(空格、回车、制表符等)。安全写法:
1
scanf("%15s", buf); // 最多读 15 个字节 + 1 个 '\0'
read(0, buf, count)如果
count大于给buf的实际大小,则会溢出。1
2char buf[32];
read(0, buf, 0x100);
结构体字段劫持
最简单的攻击目的便是修改写入变量附近的某个变量的值。比如说在下面这个例子里:
1 |
|
我们写入的变量为user这个struct里的name,但是由于输入长度限制为200,而实际的name的存储空间仅为64,并且struct里的内容的存储空间是连续的,所以可以通过输入
1 | 'A'*64 + '\x01\x00\x00\x00\x00\x00\x00\x00' |
将原本的is_admin的值修改为(被覆盖掉为)1。(注意大部分架构都是使用的小端序,并且int的大小为4个Byte,所以是\x01\x00\x00\x00\x00\x00\x00\x00)
ROP(Return Oriented Programming)
ROP(返回导向编程)指的是我们通过漏洞覆盖返回地址,并在栈上布置一条返回链(ROP Chain),使程序在不断执行ret时依次跳转到一系列以ret结尾的gadget,从而把程序/库中已有的指令片段组合成所需的执行流程(例如调用system、触发syscall、ORW读flag等)。
因为要覆盖修改返回地址,所以我们需要精确计算我们注入的起始点到返回地址的偏移。
比如说在这个例子里:
1 | | buf | 0x20 |
偏移就是0x28。这个偏移很多时候也可以用IDA直接查看栈结构来得到,只不过偶尔IDA的偏移会不准确,这个时候就只能依靠GDB调试来确认。
这个时候通过
1 | payload = b"A" * 0x28 + p64(fake_ret_addr) |
就可以将返回地址修改成fake_ret_addr。
需要注意的是,如果栈溢出的漏洞点是在函数fun()的栈上,那么当fun()执行完之后才会跳转(返回)至我们给定的fake_ret_addr。main()函数的话同理,因为main()函数也有返回地址。
ret2text
ret2text(Return-to-Text)即控制程序执行程序本身已有的的代码 (即, .text 段中的代码) 。
这种Exploit一般需要:
1 | Stack: No canary found |
如果开启了PIE,则需要先泄露基址,再计算所需函数的实际地址。
例子(假设程序中原本有一个不需要参数的win()函数,它会调用system("/bin/sh")。):
1 | win_address = 0x0000000000401172 # win函数地址0x401172 |
ret2shellcode
Shellcode
shellcode是一段用于利用软件漏洞而执行的16进制机械码,以其经常让攻击者获得shell而得名。(维基上的定义:https://zh.wikipedia.org/wiki/Shellcode)
比较常用的:
1.
1 | from pwn import * |
2.
1 | sc = asm(""" |
3. 24位的shellcode(来源:https://www.exploit-db.com/exploits/43550 ):
1 | /* |
4. 23位的shellcode(来源:https://www.exploit-db.com/exploits/36858 ):
1 | /* |
ret2shellcode
ret2shellcode(Return-to-Shellcode)指的是:
在利用栈溢出等漏洞时,将自己编写的shellcode注入到内存(常见是栈/堆/.bss)里,再通过覆盖返回地址或利用跳转gadget(如 jmp *sp)把控制流重定向到该shellcode,从而直接执行任意指令。
先只关注将shellcode写入stack并执行:
这种Exploit一般需要:
1 | NX: NX enabled #重中之重 |
我们分成开启/关闭ASLR的2种情况来讨论。
1. 开启ASLR:
1 | int main() |
假设我们可以获取到在stack上的buf的地址(在这个例子里程序会直接给我们)
所以可以构造这样的payload:
1 | from pwn import * |
先将shellcode写进buf,然后修改返回地址让程序跳转至buf的位置执行shellcode。
假如无法直接获得buf的地址,但是buf的地址会被存进rsi之类的寄存器,且程序里有类似jmp rsi的gadget。这种情况下我们就可以利用这个gadget跳转至buf的位置:
1 | from pwn import * |
2. 关闭ASLR:
由于关闭了ASLR,所以我们可以在将shellcode写入进stack后直接通过爆破栈地址来执行shellcode。
如果按照这样的Payload结构:
1 | [Shellcode] [Return Address] |
来爆破地址的话,效率会非常低,因为我们必须精确地爆破到Shellcode(buf)一开始的地址,地址高一位低一位都会失败。
为了提高爆破效率以及成功率,我们可以利用一个叫做NOP Sled的方法:
NOP 是 “No Operation”(不执行任何操作)的缩写,意思就是“空指令”。CPU执行一条NOP 后,什么状态都不改,只把程序计数器往前挪到下一条指令。
- 在 x86 上,最常见的
NOP的机器码是0x90。
而当我们将一段很长的NOP添加在我们shellcode前面,就会让我们爆破的难度大大降低。因为我们不再需要精准地返回到shellcode一开始的地址,只要它返回到NOP中的任意位置,就会自动“滑“(这也是“sled”“雪橇”这个词的由来)到后面的shellcode并执行它。
优化后的shellcode的结构:
1 | [Padding] [Return Address] [NOP] [Shellcode] |
或者
1 | [NOP] [Shellcode] [Return Address] |
这样一来,我们爆破地址的中间的间隔可以直接设置成NOP的长度,这样并不会错过我们的NOP以及Shellcode,确保了爆破一定能成功并且提高了爆破的效率。
只不过NOP sled的长度会受限于overflow漏洞的长度。如果是scanf之类任意长度写入的漏洞,则sled可以非常长,效率也会更高。
1 | from pwn import * |
ret2plt
ret2plt指的是:通过覆盖返回地址,跳转到程序的PLT (Procedure Linkage Table)表项中执行特定的函数。
也就是说我们会用程序里已经有(调用过)的函数和gadget来构造ROP,所以常用于程序里已经调用过system函数的情况。
我们分几种情况讨论:
1. 假设程序里有system函数和"/bin/sh"字符串,并且有pop rdi ; ret这个gadget。
我们可以这样构造payload,直接调用system,然后通过pop rdi ; ret把"/bin/sh"字符串作为参数传递给它:
1 | from pwn import * |
如果没有"/bin/sh","sh"也可以拿来用。在大部分情况下这两个字符串作为传递给system的参数在功能上是没有区别的。
1 | pop_rdi = p64(next(elf.search(asm('pop rdi ; ret', arch='amd64')))) |
2. 假设程序里有system函数,pop rdi ; ret这个gadget,以及一个写入的函数(比如说gets,read,scanf等)。
1 | from pwn import * |
ret2libc
ret2libc(Return-to-Library)指的是:
在存在栈溢出等漏洞、但无法直接执行注入的shellcode(通常因为DEP/NX保护禁止在栈上执行代码)的情况下,攻击者将程序的控制流劫持到libc库中的现成函数/字符串,比如 system()、/bin/sh,从而达到执行任意命令的目的。
因为需要利用libc的函数,所以一般攻击流程分为2步:
泄露libc基址
利用libc基址计算所需函数/gadget的正确地址并构造ROP链
1. 假如服务器关闭了ASLR,那么就可以直接爆破libc的基址:
1 | libc = ELF('./libc-2.41.so') |
ret需要看情况,因为有栈对齐的问题,所以有些时候需要加有些时候不需要。
2. 正常开启ASLR的情况:
一般情况是通过先泄露某个函数的实际地址,然后通过这个地址计算libc的实际base地址,最后再计算其他所需的地址。
例子:(假设泄露出了prinft的实际地址)
1 | libc = ELF('./libc-2.41.so') |
ret2dlresolve
ret2dlresolve 是一种利用 Linux 动态链接器(Dynamic Linker)的延迟绑定(Lazy Binding)机制来劫持程序控制流的技术。
核心优势: 不需要泄露 libc 基址。即便服务器开启了 ASLR,只要程序没有开启 Full RELRO(即开启了延迟绑定),且我们有一个可控的栈溢出和一块已知地址的可写内存(如 .bss),我们就可以利用这个技术伪造解析请求,让动态链接器帮我们“解析”出 system 函数的地址并直接调用。
原理简述:
回顾背景知识中提到的延迟绑定过程: 当程序第一次调用 printf@plt 时,最终会调用 _dl_runtime_resolve(link_map, reloc_index)。
link_map:链表结构的指针,包含库的信息。reloc_index(在32位是偏移,64位是索引):用于在重定位表(.rel.plt/.rela.plt)中找到修正信息。
正常流程是:
- 链接器根据
reloc_index找到重定位表项。 - 根据表项中的索引找到符号表(Symbol Table)项。
- 根据符号表项中的索引找到字符串表(String Table)中的函数名(如 “printf”)。
- 链接器去 libc 里查找 “printf”,算出实际地址,填回 GOT 表并调用。
漏洞利用点: _dl_runtime_resolve 极其“信任”传入的 reloc_index。 如果我们传入一个非常大的、精心计算的 reloc_index,使其越界指向我们自己在 .bss 段伪造的数据结构:
- 伪造的重定位表项 -> 指向伪造的符号表项。
- 伪造的符号表项 -> 指向伪造的字符串(内容为 “system”)。
那么链接器就会地去libc里查找 “system”并调用它。
手动构造 ret2dlresolve 的 payload 非常麻烦,尤其是在 64 位环境下,还需要处理复杂的结构体对齐和版本检查问题。不过好在pwntools里有现成的payload构造函数Ret2dlresolvePayload。
Exploit模板:
1 | from pwn import * |
SROP
SROP (Sigreturn Oriented Programming) 的核心在于利用Linux内核的一个机制:系统调用rt_sigreturn (Syscall number 15)。
什么是 rt_sigreturn?
当Linux进程处理信号(Signal)时,内核会把当前所有的寄存器状态(Context)保存到栈上,形成一个 SigreturnFrame,然后去执行信号处理函数。 当处理函数执行完,程序需要恢复原来的状态,就会调用 rt_sigreturn。
- 重点:
rt_sigreturn会无脑地从栈上读取数据,并把它们填回 CPU 的所有寄存器(RIP, RSP, RDI, RSI, RAX, …)。
所以当我们手动伪造一个SigreturnFrame放在栈上,然后强行触发syscall 15,内核就会把我们要执行的恶意参数(比如 execve("/bin/sh"))全部加载进寄存器。
我们来看一个简单的例子:
1 | global _start |
程序首先会直接泄露rsp的内容(栈顶地址),而程序会将rsp指针所指位置的的8个字节当成返回地址。所以执行ret命令时,程序会返回(跳转)到rsp指针所指位置,并且将rsp的值+8(rsp+=8)。
我们分2步进行:
1. Payload A: 布置好假的 Frame,并让程序重新执行一次 read。
1 | +-----------------------+ <-- 栈顶 (RSP) (栈的最低地址) |
2. Payload B: 仅仅为了控制 RAX 的值变成15,并触发 syscall。
1 | +-----------------------+ |
因为fake SigreturnFrame的前7位没有什么重要内容,所以被padding覆盖了也不影响。
第二轮执行结束后,因为程序读取了15个字节,所以rax的值会被设置成15,此时stack的内容:
1 | +-----------------------+ <-- 栈顶 (RSP) |
也就是说,此时的 CPU 状态是:
RIP:指向syscall指令。RAX:15 (sys_rt_sigreturn)。RSP:指向Fake Frame的开头。
所以程序会执行sys_rt_sigreturn,并且把我们的Fake Frame当成正常的SigreturnFrame,并且安装frame的内容重新设置寄存器的值。
1 | from pwn import * |
FSOP
FSOP (File Stream Oriented Programming,面向文件流的编程) 的核心在于劫持GLIBC中的标准输入输出流结构体:_IO_FILE。
什么是 _IO_FILE?
在 Linux 中,每一个文件流(如 stdin, stdout, stderr 或你用 fopen 打开的文件)在底层都对应一个 _IO_FILE 结构体。为了实现多态,这个结构体的末尾包含一个名为 vtable 的虚函数表指针。 当程序执行 fread, fwrite, fclose 等操作时,它并不会直接调用某个固定函数,而是通过 vtable 找到对应的函数指针并跳转执行。
在 GLIBC 2.24 版本之前,系统不会对 vtable 的合法性进行任何检查。只要我们能控制 _IO_FILE 结构体的内容,就能通过修改 vtable 指针,让程序在执行文件操作(如 fclose)时,跳转到我们的 getshell 函数。
我们来看一个简单的例子:
1 | int main() |
程序将 buf 强制转换为了 FILE * 指针。这意味着当我们执行 fclose(fp) 时,系统会从 buf 开始解析 _IO_FILE 结构体。
布局思路:
在 64 位系统中,_IO_FILE 结构体的长度大约是 0xD8 字节。我们需要在 buf 中布置以下关键数据:
_flags(Offset 0x0):设置为安全值(如0xfbad208b或0),防止fclose逻辑提前终止。_lock(Offset 0x88):GLIBC 2.23 的fclose会触发加锁操作。我们需要让这个指针指向一块内容全为\x00的可写内存(如buf + 0x10),否则程序会崩溃。vtable(Offset 0xd8):这是重中之重。我们将它指向我们伪造的虚表地址(如buf + 0x100)。- Fake Vtable (Offset 0x100):在虚表的偏移
0x10处填入getshell地址。因为fclose会调用vtable中的_IO_FINISH(位于虚表第三项)。
Payload 布局如下:
Plaintext
1 | +-----------------------+ <-- buf 起始地址 (fp 指向这里) |
Exploit 代码实现
1 | from pwn import * |
劫持控制流/Control Flow Hijack
劫持控制流(Control Flow Hijack)就是修改某个函数的GOT或者是PLT的内容。
由于GOT,PLT表的地址比栈的要低,所以无法通过栈溢出实现这种攻击,而是需要堆(Heap)上的溢出,或者是任意写入的漏洞。
我们来看一个简单的例子:
1 |
|
由于程序的漏洞,我们这里可以控制i和buf的内容。所以我们这里可以获得一个任意写入的权限。
假设我们通过其他办法得到了system函数的真实地址,那么我们就可以把atoi@got里的内容修改成system的地址,这样一来,当程序进行到atoi时,它会通过plt和got来调用got里写的函数地址,也就是system的地址。当我们再给buf输入"/bin/sh"的时候,程序执行原本的atoi(buf)时候实际上会执行system(buf),由此拿到shell。
当程序没有循环的时候我们需要将程序结束前会调用的某个函数修改成main的地址,使得程序会循环运行main函数。
简单来讲,劫持控制流就是修改程序的got表里的内容,使得程序以为自己在运行函数fun1的时候,实际上在运行fun2,依次来达到目的。这种操作相对于ROP来讲会更加间接一点。在之后堆利用的部分会经常用到。
栈金丝雀/Stack Canary
为了预防潜在的栈溢出的威胁,人们发明了名为Stack Canary(栈金丝雀)的安全机制。
名字的由来/历史背景:
在 19 世纪和 20 世纪早期,还没有先进的电子传感器。矿工下井挖掘煤矿时,最害怕的就是无色无味的一氧化碳 (CO)或瓦斯(甲烷)泄漏。一旦发现,通常为时已晚。
矿工们发现,金丝雀(Canary)这种鸟类对有毒气体极其敏感。由于它们的新陈代谢很快,只要空气中有一丁点毒气,金丝雀会比人类更早出现中毒反应(停止歌唱、晕倒甚至死亡)。
因此,矿工下井时会提着一个装着金丝雀的笼子,类似于一个警报器:
- 只要鸟还在叫,说明环境是安全的。
- 一旦鸟不叫了或倒下了,矿工就知道危险逼近,必须立即撤离。
回到计算机的部分:
Stack Canary(栈金丝雀)的核心思想非常简单:在局部变量(缓冲区)和控制信息(如返回地址)之间放置一个随机生成的整数(即 Canary)。
在函数返回之前,系统会检查这个值是否被修改。如果发生了缓冲区溢出,攻击者的数据通常是从低地址向高地址覆盖的,那么在覆盖到返回地址之前,必然会先覆盖掉 Canary。一旦系统发现 Canary 变了,就会立即终止程序,从而阻止攻击。
比较有意思的是,我们可以做一个完美的对应(类似比喻的那种):
| 现实世界 (煤矿) | 计算机世界 (内存栈) |
|---|---|
| 矿井 | 程序栈 (Stack) |
| 矿工 | 返回地址 (Return Address) |
| 毒气/瓦斯 | 缓冲区溢出数据 (Buffer Overflow) |
| 金丝雀 (Canary) | Canary值 (随机整数) |
| 鸟死了 | Canary值被修改 |
| 撤离矿井 | 程序终止 |
开启了canary的栈布局:
1 | 高地址 (High Address) 0xFF... |
此外还有一点,在 Linux (GCC/glibc) 以及大多数现代操作系统的实现中,x86/x64架构下的Stack Canary的最低位(Least Significant Byte, LSB) 几乎总是被强制设置为0x00。
(因为x86/x64是小端序 (Little-Endian) 架构,所以最低位会被存在低地址,也就是上面结构里离局部变量最近的那位。)
这个 0x00 主要有两个防御目的,特别是针对 C 语言中常见的字符串操作函数:
- 防止泄漏 (Anti-Leak / Read Protection)
- C 语言的字符串打印函数(如
printf("%s", buf),puts(buf))是依靠\0(0x00) 来判断字符串结束的。 - 如果攻击者利用漏洞读取栈上的内容(例如 buffer 没有正确的结束符),程序会一直向高地址打印。
- 当打印遇到Canary的第一个字节
0x00时,打印函数会认为“字符串结束了”,立即停止。 - 也就是说:我们只能读到填充的垃圾数据,而读不到 Canary 后面的 7 个随机字节。保护了 Canary 的秘密性。
- C 语言的字符串打印函数(如
- 防止特定写入 (Anti-Overwrite / Write Protection)
- 字符串复制函数(如
strcpy)遇到0x00会停止复制。 - 虽然这不能完全阻止缓冲区溢出(仍可以用
memcpy或read这种不看\0的函数来覆盖),但它限制了攻击者使用strcpy这类函数来精准修改Canary之后的返回地址而不破坏 Canary的难度。
- 字符串复制函数(如
栈金丝雀可以非常有效地防御那种连续性的overflow漏洞/线性溢出(Linear Overflow),但是仍有些情况它是照顾不到的:
1. 假如有信息泄露漏洞(比如 Format String 漏洞,或者可以越界读取 Stack 内容),那么我们就可以直接把canary的完整的值泄露出来,覆写时注意把canary部分覆写成正确的值即可。
2. 假如有数组越界写入漏洞(Out-of-Bound Write),那么就可以指定索引写入,从而直接绕过canary来修改返回地址等内容。
3. 假如常驻主程序使用fork()来生成子进程处理每个连接,并处理所有逻辑,那么就可以尝试爆破canary的值。
fork() 不会重新随机化 canary:父进程的 TLS/TCB(存 canary 的地方)会COW(copy on write)复制给子进程。
所以所有子进程的 canary 都一样(直到父进程重启)。也就是说,每次连接的时候,canary的值都一样。
除此之外,进程在 exec 时才做一次 ASLR 随机化:PIE 基址、libc 基址、栈基址、canary 等都在这时确定。
并且fork() 不会重新随机化地址空间,而是把父进程当前的内存映射按COW(copy on write)原样克隆给子进程。
因此,同一轮服务存活期间,所有子进程都会共享这些不变的东西:
- stack canary 值(最低字节 0x00),
- PIE / libc 的装载基址(所以代码里的绝对返回地址一致),
- 栈/堆/各段的虚拟地址布局(所以函数帧的 saved RBP 和 RET 会落在相同的虚拟地址,并且内容一致:
saved rbp是上个帧的栈地址;ret是固定的“调用点下一条指令”的地址。
调用序列相同 → 它们在每个子进程里都相同。)
所以说在这种情况下,我们可以根据Orcacle来一位一位地爆破canary的值:一位一位地覆盖canary的值,根据程序是否有正常执行之后的内容来判断尝试是否正确。
4. 主线程生成了一个子线程来处理所有的逻辑。
在Linux (glibc) x86_64环境下:
- 主线程:栈(Stack)和 TLS(Thread Local Storage)通常在内存中相距甚远。栈在极高的内存地址向下增长,而 TLS 位于加载的库附近。
- 子线程 (pthread):栈和 TLS 是紧邻的。
pthread_create会使用mmap分配一块连续的内存区域作为该线程的栈空间。
内存视图:
1 | 高地址 (High Address) |
程序退出时,会将栈里的canary值与master canary的值进行比较,如果不一样就会直接退出。
所以如果可以同时覆盖掉栈里的canary和TLS中的master canary,便可以绕过canary的检测进行任意的ROP。
注意:大部分指针只接受valid的值或者是null,所以在这种需要覆盖很多内容的情况时需要格外注意。(需要一点一点debug,非常折磨)
格式化字符串漏洞 Format String Vulnerability
我们首先来看一下什么是格式化字符串函数。
格式化字符串函数
格式化字符串( format string)函数可以接受可变数量的参数,并将第一个参数作为格式化字符串,根据其来解析之后的参数。
可以参考这个定义:
The format string is a character string which contains two types of objects: plain characters, which are simply copied to the output channel, and conversion specifications, each of which causes conversion and printing of arguments.
(来源:https://ocaml.org/manual/5.0/api/Printf.html)
一般来说,格式化字符串在利用的时候主要分为三个部分
- 格式化字符串函数
- 格式化字符串
- 变量,可选
例子:
1 |
|
格式化字符串函数
分为输入和输出,其中
- 输入:
| 函数 | 说明 |
|---|---|
scanf() |
从标准输入读取数据 |
基本语法:
1 | scanf("格式字符串", &变量1, &变量2, ...); |
例子:
1 |
|
注意:scanf("%s", name); 不需要加 &,因为数组名本身就是地址。
- 输出:
| 函数名 | 说明 |
|---|---|
printf |
向标准输出(通常是终端)打印格式化字符串 |
fprintf |
向指定文件流打印格式化字符串(如 stderr, 文件指针等) |
sprintf |
将格式化的字符串写入字符数组(注意缓冲区溢出风险) |
snprintf |
将格式化的字符串写入字符数组,指定最大写入长度,更安全 |
asprintf |
将格式化字符串写入动态分配的内存(GNU 扩展,非标准 C) |
dprintf |
向指定的文件描述符写入格式化字符串(POSIX,常用于系统编程) |
vprintf |
类似 printf,但参数通过 va_list 传递(用于变参函数) |
vfprintf |
类似 fprintf,参数为 va_list |
vsprintf |
类似 sprintf,参数为 va_list(不安全) |
vsnprintf |
类似 snprintf,参数为 va_list(推荐用于变参安全格式化) |
格式化字符串
正如上面的定义里说的,格式化字符串里除了明文还有格式化占位符。我们这里来重点关注一下这个格式化占位符。
格式化占位符(conversion specifications)的语法如下:
1 | %[parameter][flags][field width][.precision][length]type |
- Parameter:指定用于格式化的参数位置(从1开始)
| 字符 | 说明 |
|---|---|
n$ |
其中n是参数位置 |
例子:
1 | printf("%2$d %1$d", 11, 22); |
- Flags:
| 标志 | 说明 |
|---|---|
- |
左对齐(默认是右对齐) |
+ |
总是显示正号或负号(例如 +10) |
(空格) |
正数前加空格,负数前加负号 |
0 |
用0填充未占满的宽度 |
# |
对于%o、%x、%X等,添加前缀(如0x);对于%f等,始终包含小数点 |
- Field Width:指定最小输出字符数,不足时用空格(或0)填充,如果要使用变量指定宽度,可以用 *。
例子:
1 | printf("%d", 42); |
- Precision:指定数字小数点后的位数或字符串的最大输出长度:
- 对于浮点数(如
%f):表示小数点后保留的位数,如%.2f - 对于字符串(如
%s):表示最大输出字符数,如%.5s - 可以使用
*表示由参数动态提供
- Length:指出浮点型参数或整型参数的长度
| 修饰符 | 说明 |
|---|---|
hh |
signed char 或 unsigned char |
h |
short 或 unsigned short |
l |
long 或 unsigned long |
ll |
long long 或 unsigned long long |
L |
long double(用于%Lf) |
z |
size_t |
t |
ptrdiff_t |
j |
intmax_t 或 uintmax_t |
例子:
1 |
|
- Type:也称转换说明(conversion specification/specifier),指定具体的数据类型,有以下选择
| 字符 | 说明 |
|---|---|
%p |
打印指针(十六进制地址) |
%x |
打印十六进制(小写) |
%s |
打印字符串(char*),即打印某个地址里的内容。 |
%.2f |
打印浮点数,保留小数点后2位 |
%f |
打印浮点数(float/double) |
%c |
打印单个字符(char) |
%d |
打印十进制整数(int) |
%% |
输出一个百分号 % |
其中只有Type是必须要给的,其他均可以省略。
例子:
1 |
|
注意:在第二部分一定要给定变量,如果没有给,则会从错误的内存地址读取数据,导致不可预期的行为。
此外还有一个比较特殊的格式符:%n 。这个格式符会让 printf 把当前已经打印的字符数量写入n。(或者说写入给定的地址。)
比如说下面这个例子(正常用法)
1 |
|
n的值会被存储为5。
由于它的特殊性以及危险性,很多现代系统在libc中禁用了 %n,或者在格式化函数上增加了保护(如glibc中对 %n 的格式检查)。
不过正是因为它的危险性所以我们在pwn里经常会用它来修改内存数据
变量
希望输出的变量。
格式化字符串漏洞
正常情况:
在进入printf函数之后,函数会首先获取第一个参数,一个一个读取其字符会遇到两种情况
- 当前字符不是
%,直接输出到相应标准输出。 - 当前字符是
%, 继续读取下一个字符- 如果没有字符,报错
- 如果下一个字符是
%, 输出% - 否则根据相应的字符,获取相应的参数,对其进行解析并输出
例子:
1 |
|
参数是怎么传进 printf 的(32-bit 和 64-bit)
32-bit(cdecl)——全部走栈
- 变参有“默认实参提升(default argument promotions)”:
float会提升为double(占 8 字节),char/short提升为int。 - 典型调用时栈的示意(自上而下是低地址 → 高地址,或按“调用现场从下往上”理解也可以):
1 | +------------------------------+ |
printf 在解析到 %d/%f/%s 时,会从“第一个可变参数槽位”开始,依次取“4B/8B/指针”的值并格式化输出。
x86-64(System V ABI)——寄存器优先 + 溢出到栈
- 前 6 个整数/指针类参数:
RDI, RSI, RDX, RCX, R8, R9 - 前 8 个浮点类参数:
XMM0–XMM7(float仍提升为double) - 变参函数还会准备一个寄存器保存区(register save area)和栈溢出区(overflow area)。
va_list/va_arg会按参数类型从对应区域顺序取值;寄存器名额用完后改从栈上取。
对应上面的例子,调用瞬间常见分配为:
RDI="Int: %d, Float: %f, String: %s\n"(格式串)RSI=a(%d)XMM0=b的 double(%f)RDX=str(%s)
在64-bit架构下不是所有参数都在栈上。printf 通过 va_list 维护“当前吃到第几个槽位”,按类型先从寄存器保存区拿,超出再从栈拿;这就是为什么64-bit 下偏移(offset)和 32-bit 不同,必须现场探测或用 %n$ 显式参数序号。
特殊情况以及偏差值
当我们在使用格式化字符串函数但未提供后续实参(即只给了 fmt 一个参数)时:
1 |
|
printf 在扫描到每个转换说明(%...)时,会依据 ABI 约定通过 va_arg 按顺序从可变参数起始位置检索下一参数槽位的内容:在 x86(32-bit) 上对应为栈槽,在 x86-64 SysV 上对应为寄存器保存区(reg_save_area)以及栈溢出区(overflow_arg_area)。
由于这些槽位未被显式赋值,读取到的将是相应存储区域中的现存(残存)/未定义数据,于是被按 %x/%p/%s 等格式解释并输出。进一步地,当该顺序读取过程推进到包含本次输入缓冲区(例如位于栈、堆或 .bss)的地址范围,且首次取到我们预置的标记(如 AAAA...)时,该标记对应的参数序号就称为偏差值 k(即从“第一个可变参数槽位”开始计数,到首次命中标记之间的槽位数量)。这样一来,我们即可使用显式参数序号(如 %k$p, %k$s, %k$n)稳定地指向目标槽位进行泄露或写入。
漏洞表现
在CTF的题目里这个漏洞一般的表现如下:
1 |
|
我们可以利用这个漏洞读取栈上的内容(如变量值、返回地址等)或者通过 %n 格式符(就是我们之前提到的那个危险的格式符)向指定内存地址写入数据。
Exploit技巧
读取栈上的内容
1 | printf("%x %x %x"); |
1 | printf("%p %p %p"); |
%x:以十六进制整数形式输出栈上的内容。%p:以指针形式(十六进制地址)输出栈上的内容。
1 | payload = b"%p " * 40 |

或者也可以使用%n$p:
1 | payload = "%1$p %2$p %3$p %4$p %5$p %6$p %7$p %8$p %9$p %10$p" |
1 | payload = " ".join([f"%{i}$p" for i in range(1, 61)]).encode() |

读取任意地址的字符串
%s:把 栈上的值当成一个指针地址,并尝试打印这个地址指向的内存,直到遇到\0。
假设栈上某个参数的值是:
1 | 0x08049000 → 指向 "HelloWorld" |
用 %x和%p会输出
1 | 8049000 |
用%s则会输出
1 | printf("%s"); |
一般流程
确定偏移
S(offset):输入形如
AAAA,%p,%p,%p...看第几个%p能读出我们可控的标记(比如0x41414141),得到偏移S。使用下面的方法构造payload
假如我们确定了偏移,并且知道了flag的具体地址,那么我们便可以用以下的payload直接读取flag的内容:
1 | def fmt_read_addr_payload(offset, addr, k=1): |
其中:
offset是我们确定的偏移
addr是我们希望读取的内容的地址
8*k主要用于对齐。(如果k=1不行,可以尝试k=4,貌似比较稳。)
因为
p64(addr)直接接在格式串后面,如果没有按8字节对齐,它大概率不会正好落在第offset个槽位上,也就会导致读取出问题。
写入
一般流程
确定偏移
S(offset):
输入形如AAAA,%p,%p,%p...看第几个%p能读出我们可控的标记(比如0x41414141),得到偏移S。放置目标地址(避免
\x00截断):- 把“格式化指令(全 ASCII)”放在前面;
- 把目标地址(或一串地址)放在 payload 末尾;
- 用位置参数
%K$...来点名这些地址(K从S + ceil(len(fmt_ascii)/8)起)。
对齐/padding:
written= 到当前为止已输出字符数;目标值
want(希望被写入到内存里的数值,按写入宽度取模);计算:
1
2
3
4
5
6
7base = 256 #(%hhn,1字节)
base = 65536 #(%hn,2字节)
base = 2**32 #(%n,4字节)
base = 2**64 #(%ln/%lln,8字节)
pad = (want - (written % base)) % base
# 如果 pad == 0,为了稳妥可用 pad = base(等价“加 0”)base为取值范围,分别等于1,2,4,8字节的最大值。
然后输出
%padc(或其他等价方式)把written调到想要的值。
执行写入:
%K$hhn写 1 字节%K$hn写 2 字节%K$n写 4 字节(int*)%K$ln/%K$lln写 8 字节(long*/long long*,在 x86_64 都是 8Byte)
对 %hn/%n/%ln 这类多字节写,最好按“从小到大”的目标值排序写入,避免 padding 需要“回绕”到很大的数。或者直接用逐字节写 %hhn。
写 1 字节(%hhn)
示例 1:把 pwnme_addr 的最低 1 字节写成 0x90
假设已经测得偏移 S = 10,并用
BASE = S + ceil(len(fmt_ascii)/8) 计算出第一个地址是第 K=BASE 个参数位。
1 | # 目标:*(uint8_t*)pwnme_addr = 0x90 |
若此时 written % 256 不是从 0 开始,照公式算:pad = (0x90 - (written%256)) % 256,用 %padc 形成 padding。
fmtstr_payload
Pwntools里有现成的高效构造这种payload的函数:
1 | fmtstr_payload(offset, writes, numbwritten=0, write_size='byte') |
(官方文档:https://docs.pwntools.com/en/dev/fmtstr.html )
参数(摘译):
offset:第一个可控“参数槽”的位置(即你测出来的%n$p起点)。writes:要写入的目标,字典{address: value, ...}。(将value写进address里)numbwritten:调用printf前已经输出的字节数(影响对齐/填充计算)。write_size:原子写入粒度,'byte'|'short'|'int'|'long'等。
堆利用/Heap Exploitation
堆利用(Heap Exploitation)和核心/最终目的是劫持分配器 (Hijacking the Allocator),让其误以为敏感地址(如 GOT 表、栈上的返回地址、Hook 函数指针)是空闲链表里的一块普通内存,并将其分配给我们,以达到任意写入的目的。当然在此之前还需要信息泄露用于确定我们该往哪里进行写入。
首先先区分一下libc和glibc:
libc(C Library)通常指的是标准 C 库。它是一套基础函数的标准规范。
比如说标准(libc)只规定了
malloc和free怎么用。glibc(GNU C Library)是 GNU 项目对上述 libc 标准的具体代码实现。
会决定具体如何管理堆内存(Chunk 结构、Bin 链表、Tcache 机制)。

Chunk(堆块)结构: 堆内存被划分为一个个 Chunk。每个 Chunk 包含头部信息(Header)和用户数据区 :
- 头部字段 (Header):
prev_size:如果前一个物理相邻的 Chunk 是空闲的,这里存储前一个 Chunk 的大小;如果前一个是使用中的,这里归属于前一个 Chunk 的用户数据区 。size:当前 Chunk 的大小,低 3 位用于存储标志位(如prev_in_use,表示前一个块是否在使用中) 。- 空闲时的指针: 当 Chunk 被释放(Free)后,用户数据区的前 16 字节会被复用为
fd(Forward Pointer) 和bw/bk(Backward Pointer),分别指向链表中的下一个和上一个空闲块 。
- 内存布局:堆是从低地址向高地址增长的。Chunk 的大小通常以
0x10(16字节)对齐 。
堆管理列表 (Bins): glibc使用多种链表(Bins)来管理空闲的Chunk,以提高分配效率。常见的几种:
- Fastbin:
- 单向链表 (Singly-linked),LIFO (后进先出) 。
- 管理小块内存,大小范围
[0x20, 0x80]。 - 每个大小都有独立的链表 。
- Tcache (Thread Local Cache):
- 最重要特性: glibc 2.26 引入,为了性能设计,每个线程独有。
- 单向链表,LIFO 。
- 大小范围
[0x20, 0x410]。 - 分配和释放优先级最高,且默认不进行合并 。
- 每个链表最多容纳 7 个块 (Count=7) 。
- Smallbin:
- 双向链表 (Doubly-linked),FIFO 。
- 大小范围
[0x20, 0x400]。
- Unsorted Bin:
- 双向链表,仅有一个列表 。
- 作为缓存层,刚释放且未进入 Tcache/Fastbin 的块会先放入这里 。
- Top Chunk: 位于堆顶部的巨大空闲块,当 bins 中没有合适的块时,从这里切割内存 。
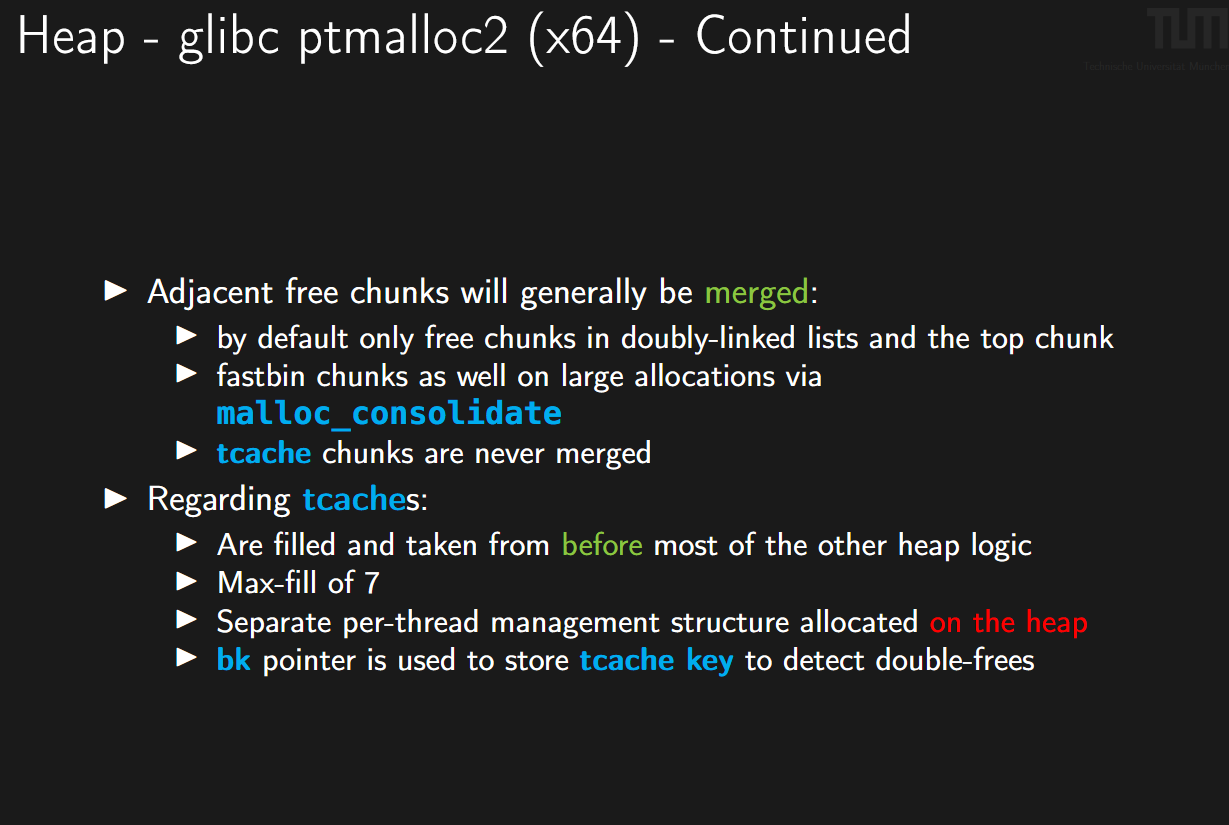
1. 空闲块的合并机制 (Merging)
glibc 为了防止内存碎片化,通常会尝试把相邻的空闲块合并成一个大块。
- 默认合并对象:
- 属于 双向链表(Smallbin, Largebin, Unsorted Bin)中的空闲块以及 Top Chunk 。
- 当你释放(free)这些块时,如果它们物理相邻,它们会立即合并。
- Fastbin 的特殊情况:
- Fastbin默认不合并(为了速度)。
- 但是,当程序申请一个较大的内存块(Large Allocation)时,会触发
malloc_consolidate函数 。 - 这个函数会清理 Fastbin,强制将里面的块进行合并,放入Unsorted Bin中。
- Tcache 的特殊情况:
- Tcache Chunks 永远不会合并 。
- 这是Tcache速度极快的原因,也是它的缺点(容易导致堆碎片,但也容易被利用来保留特定大小的空闲块)。
2. Tcache 的核心特性 (Regarding tcaches)
Tcache 是 glibc 为了提升多线程性能引入的机制,有几个关键特性:
- 优先级最高 (L1 Cache):
- 它在大多数其他堆逻辑之前被填充和提取 。
- 这意味着:
malloc时先看Tcache有没有;free时先放进Tcache。只有Tcache满了或空了,才会去操作 Fastbin/Smallbin等。
- 容量限制 (Max-fill of 7):
- 每个大小(Size Class)的链表最多只存 7 个 Chunk 。
- 攻击意义: 如果你想把一个块放入Fastbin或Unsorted Bin以触发更复杂的漏洞(如 Unsorted Bin Leak),你需要先
free7个同大小的块把Tcache填满,第8个才会落入其他Bin。
- 管理结构在堆上 (On the heap):
- Tcache的管理结构(
tcache_perthread_struct,存着链表头指针数组)本身也是分配在堆上的 。 - 攻击意义: 如果你能劫持这个管理结构,你就能控制整个线程的堆分配。
- Tcache的管理结构(
- 安全检查 (Key):
- Tcache是单向链表,原本不需要
bk指针。 - 但是为了防止 Double Free(双重释放),glibc会在空闲Tcache Chunk 的
bk位置存储一个tcache key(通常指向tcache_perthread_struct的地址)。 - 当你释放一个块时,系统会检查
bk位置是否等于这个 key,如果是,则遍历链表检查是否重复释放。
- Tcache是单向链表,原本不需要
不同libc版本的安全检查以及分配策略都是不太一样的。
Glibc 2.31
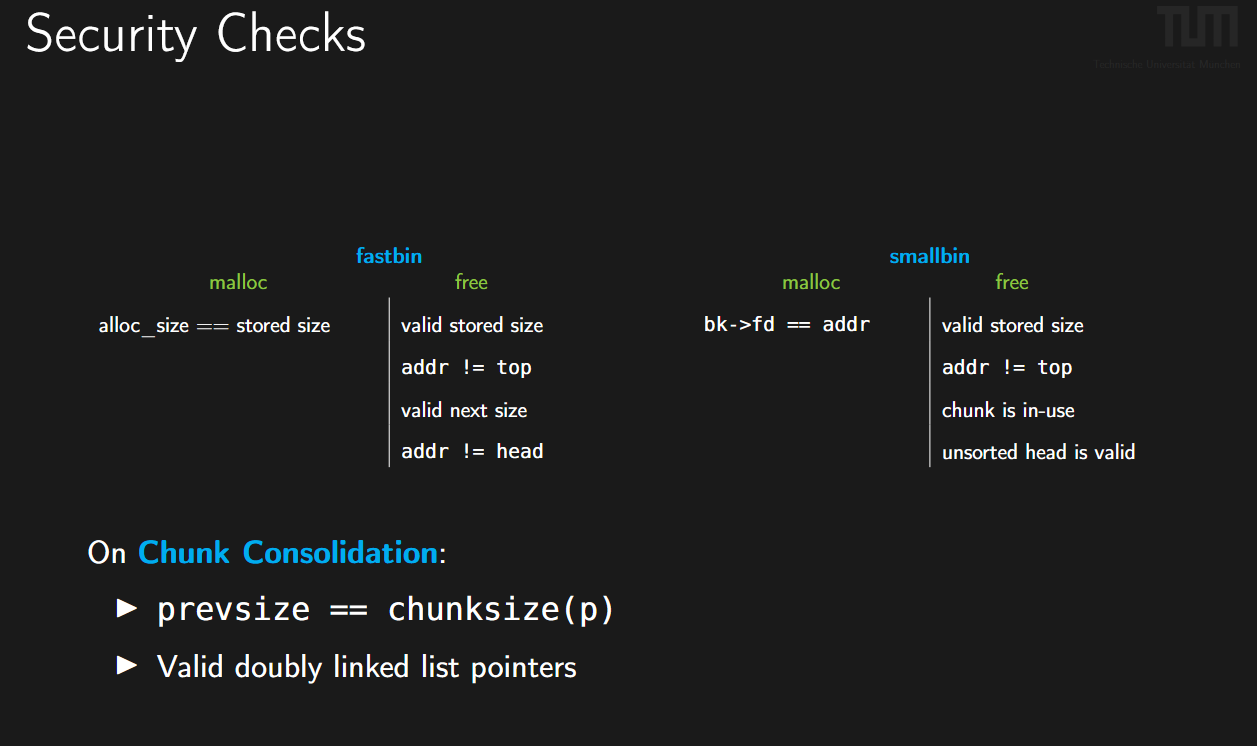
1. Fastbin 的检查:
Fastbin 是单向链表,性能仅次于 Tcache。
- Malloc:
alloc_size == stored size(Size Integrity)- 含义: 当从 Fastbin 取出一个块时,系统会检查这个块头部的
size字段,看它是否真的属于当前这个 Bin 的大小范围。 - 攻击后果: 如果你想伪造一个 Fastbin Chunk(比如在栈上伪造),你必须确保伪造地址的偏移处有一个正确的
size数值,否则程序会崩溃。
- 含义: 当从 Fastbin 取出一个块时,系统会检查这个块头部的
- Free:
valid next size: 检查内存中下一个物理相邻块的大小字段是否合理。这是为了防止因溢出导致的元数据损坏。addr != head(弱 Double Free 检查):- 它只检查链表的头节点是不是当前要释放的地址。
- 绕过: 这就是经典的 ABA 问题。你释放 A,链表头是 A;你释放 B,链表头变成 B;你再次释放 A,因为此时链表头是 B (A != B),检查通过。A 成功进入链表两次。
2. Smallbin的检查:
Smallbin 是双向链表,管理较大内存,安全性最高。
- Malloc:
bk->fd == addr(Safe Unlink)- 含义: 这是最著名的堆保护机制。当从双向链表取出一个块(Unlink)时,系统会检查:这个块的后一个块的前向指针,是否指回这个块本身?
- 公式:
P->bk->fd == P - 攻击后果: 这使得经典的“Unlink 攻击”(通过修改 fd/bk 实现任意地址写)在现代 glibc 中基本失效,除非你能同时伪造好 fd 和 bk 指向的内存内容。
- Free:
chunk is in-use:- 它会检查下一个物理相邻 Chunk 的
prev_in_use位(P-bit)。如果 P-bit 为 0,说明当前块已经是空闲状态了,系统就会报错,防止 Double Free。
- 它会检查下一个物理相邻 Chunk 的
unsorted head is valid: 针对 Unsorted Bin 的完整性检查。
3. Chunk Consolidation (块合并)
这部分指的是当Smallbin/Largebin发生物理合并时(比如你释放一个块,它发现前一个块也是空闲的,就要合并成一个大块)。
prevsize == chunksize(p):- 含义: 当前块的
prev_size脚标,必须等于前一个块头部的size。 - 目的: 防止 Off-by-one 漏洞利用(比如 Poison Null Byte 攻击)。如果攻击者偷偷改小了
prev_size试图让堆管理器“吃掉”正在使用的内存,这个检查会拦截。
- 含义: 当前块的
Valid doubly linked list pointers:- 在合并过程中,被吞并的空闲块需要从链表中移除,此时会再次触发类似 Safe Unlink 的检查。

1. Malloc 时的检查:无
它不检查取出的 Chunk 大小是否正确。
它不检查指针是否对齐。
- 它直接相信链表头部的指针(FD)。
2. Free 时的检查:
虽然 malloc 不管,但在 free 时 Tcache 还是做了一些防御,主要是为了防止 Double Free。
valid stored size- 检查你要释放的地址处的
size字段是否合法(比如大小不能太离谱,且必须对齐)。
- 检查你要释放的地址处的
key/bk != tcache_key || chunk not in tcache list(Double Free 检查)- 背景: Tcache 是单向链表,本来不需要
bk指针。glibc 这里复用了bk的位置(用户数据的第 8-15 字节)来存放一个随机生成的tcache_key(通常指向堆管理结构)。 - 逻辑: 当调用
free(ptr)时:- 系统先检查
ptr->bk是否等于tcache_key。 - 如果不等于: 系统认为这是一个新释放的块,直接放入链表,并把 key 写入
bk位置。 - 如果等于: 系统怀疑你正在 Double Free。于是它会遍历整个链表,检查里面是不是真的已经有了这个 Chunk。
- 系统先检查
- 绕过思路: 如果能利用 Use-After-Free (UAF) 改写该 Chunk 的
bk位置(把 key 覆盖掉),就可以绕过这个检查,再次释放它,从而实现 Double Free。
- 背景: Tcache 是单向链表,本来不需要
Glibc 2.41
随着libc版本的更新,发生了很多的变化,所以很多针对老版本libc的heap exploitation的攻击没有办法应用在新版的libc里。

攻击方法
1. Fastbin/Tcache FD Corruption (FD 指针篡改)
利用 Use-After-Free (UAF) 实现任意地址分配(Arbitrary Chunk Allocation)。
- 场景: 针对单向链表(Tcache 或 Fastbin)。
- 步骤:
- 释放一个Chunk A,它进入空闲链表 。
- 利用悬挂指针(UAF)修改Chunk A的
fd指针,将其指向目标地址<victim>(例如栈地址或 libc 中的 hook) 。 - 第一次
malloc取出 Chunk A 。 - 第二次
malloc就会返回<victim>地址,从而控制该区域内存 。
图示:
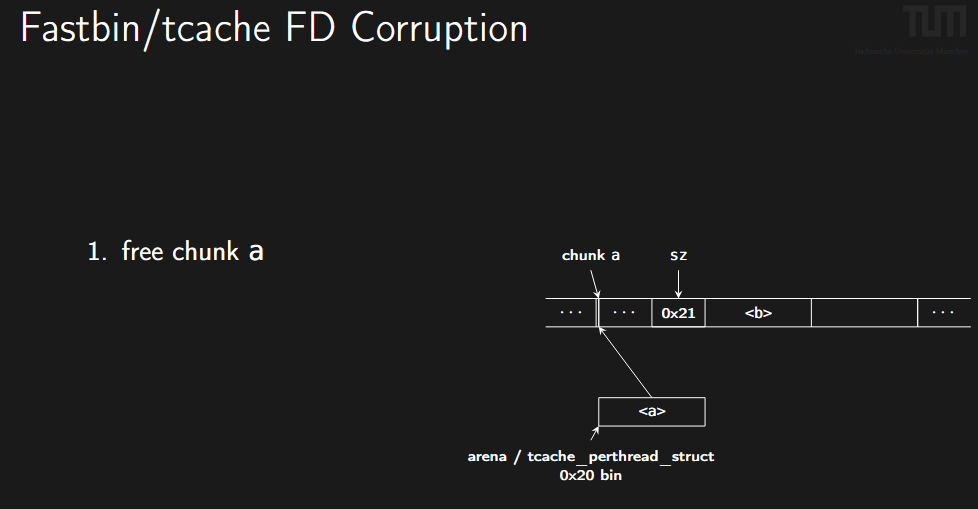

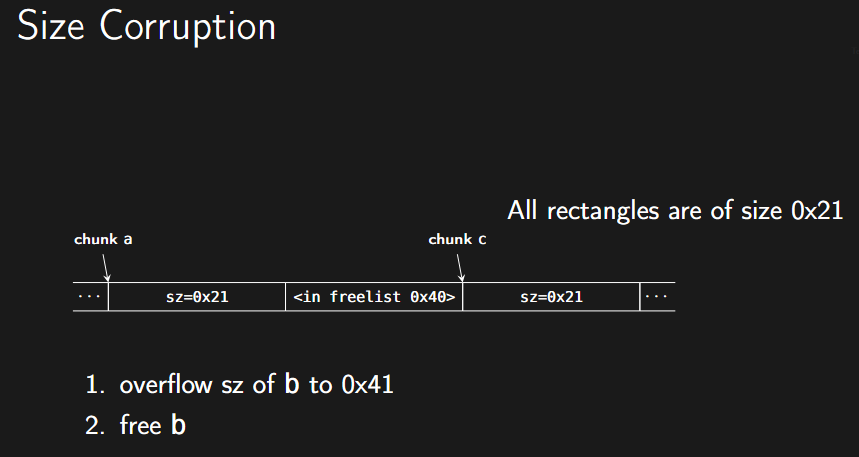
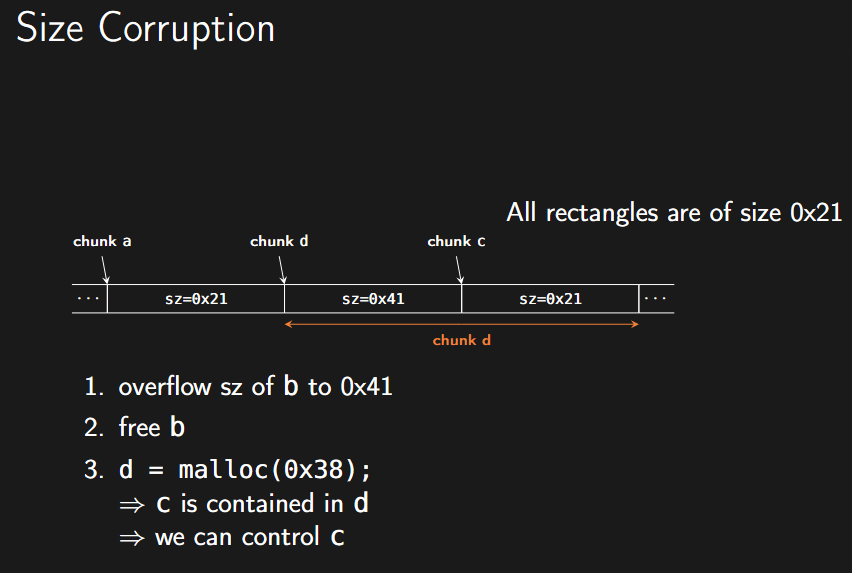
2. Size Corruption (大小篡改 / Overlapping Chunks)
通过修改 Chunk 的头部大小字段,制造堆块重叠。
- 场景:内存中有连续的Chunk A, B, C。
- 步骤:
- 利用Chunk A的溢出漏洞,覆盖Chunk B的头部 。
- 将Chunk B的
size改大(例如从 0x21 改为 0x41),使其覆盖到Chunk C 。 - 释放Chunk B 。
- 重新申请一个较大的内存(例如 0x38),系统会分配原 B 的空间,但由于大小已变,新的Chunk D会覆盖原本的Chunk C 。
- 结果: 攻击者可以通过编辑Chunk D来控制Chunk C的内容(即使用户认为 C 仍在使用中) 。
图示:


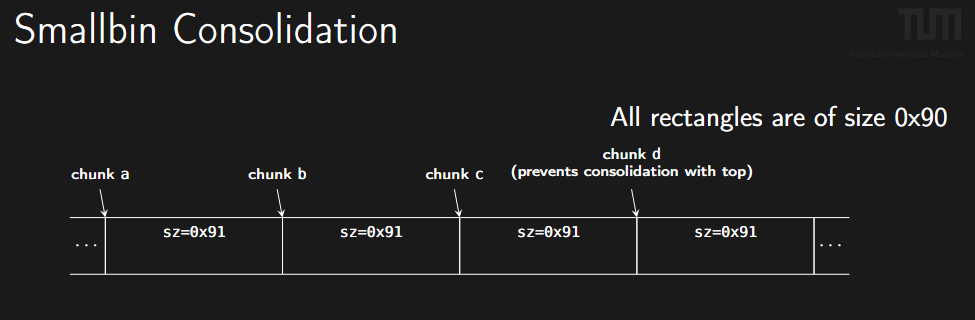
3. Smallbin Consolidation (Smallbin 合并攻击)
利用的是 malloc_consolidate 和 unlink 机制来构造重叠块(Overlapping Chunks)或绕过某些限制。
- 前提: 利用
prev_size和prev_in_use位的逻辑。 - 布局: 连续的 Chunk A, B, C, D。
- 步骤:
- 释放Chunk A(放入 Unsorted/Smallbin,建立合法的 fd/bk 指针) 。
- 利用Chunk B的溢出,修改Chunk C的头部:
- 将C的
prev_size修改为size(A) + size(B)(伪造前一个块非常大) 。 - 将C的
prev_in_use标志位置0(欺骗 C 认为前一个大块是空闲的) 。
- 将C的
- 绕过检查 (glibc 2.29+): 需要修改Chunk A的
size字段,使其等于伪造的prev_size,以通过完整性检查 。 - 释放Chunk C 。
- 触发合并: glibc 检测到 C 的
prev_in_use为 0,根据prev_size向后合并,吞并了正在使用的 Chunk B,与Chunk A合并成一个巨大的空闲块 。 - 重新申请一个大块E 。
- 结果: Chunk E完全包含了仍在“使用中”的 Chunk B,攻击者完全控制了 B 的数据 。
图示:





推荐工具
forkever (by haxkor)
功能: 允许模拟堆操作并支持检查点 (Checkpoints) 功能 。
作用: 在编写 Exploit 时,经常需要反复尝试某一步骤。这个工具可能类似于虚拟机的快照功能,让你在堆的某个特定状态下反复尝试不同的攻击载荷,而不需要每次都重新启动程序,大大提高了调试效率。
- https://github.com/haxkor/forkever
pwndbg-gui (by AlEscher)
功能: 为著名的 GDB 插件
pwndbg提供图形化界面,并增强了堆上下文 (Heap Context) 的显示 。作用: 原生的 GDB/pwndbg 是命令行界面,查看堆链表时比较抽象。这个工具通过 GUI 可视化展示 Bin 的状态,让你更直观地看到堆块是如何链接的。
- https://github.com/AlEscher/pwndbg-gui
ptrfind (by ChaChaNop-Slide)
功能: 寻找指针和指针链,以利用任意读写 (Arbitrary Read/Write) 。
作用: 在堆利用中,经常需要通过多级指针跳转找到目标地址(比如通过
environ找栈地址)。这个工具能自动化寻找这些指针路径,省去了人工计算偏移的繁琐工作。- https://github.com/ChaChaNop-Slide/ptrfind
heapvis (by Staeves)
功能: 专门针对 libc 2.31 版本的堆可视化工具 。
作用: 配合本课程讲授的 libc 版本(2.31),将抽象的堆内存布局画出来,帮助你理解 Chunk 的排列和状态。
- https://github.com/Staeves/heapvis
学习资料
- how2heap
- Malloc Maleficarium
- 比较古早但很经典的文章。
- https://packetstormsecurity.com/files/40638/MallocMaleficarum.txt.html
- 不知道为什么Chrome访问这个网址会有问题,但是Firefox就可以。
- https://heap-exploitation.dhavalkapil.com/
常用pwndbg命令
1 | # 概览 |
题目分类
- Pwn相关基础知识:
- Buffer Overflow:
- 结构体字段劫持:
- ROP:
- ret2shellcode:
- ret2text:
- ret2plt:
- CTF.show Pwn入门 Pwn 40
- 攻防世界 level2 Writeup (32位程序)
- HTB You_know_0xDiablos Writeup (32位程序)
- ret2libc:
- 5
- 格式化字符串漏洞:
- HTB racecar Writeup(利用格式化字符串漏洞读取信息。)
- 攻防世界 CGfsb Writeup (利用格式化字符串漏洞修改目标变量的值。)
- 堆利用: