
介绍
Java是一种广泛使用的计算机编程语言,拥有跨平台、面向对象、泛型编程的特性,广泛应用于企业级Web应用开发和移动应用开发。
Hello World
1 | public class HelloWorld { |
public class HelloWorld:定义了一个类,类名必须和文件名一致(区分大小写),所以这份文件必须取名为HelloWorld.java。public static void main(String[] args):这是 Java 程序的入口方法,运行时会从这里开始执行。String[] args:用来接收命令行参数,比如运行时java HelloWorld a b c,args就是["a","b","c"]。String args[]与String[] args都可以执行,但推荐使用String[] args,这样可以避免歧义和误读。
System.out.println("Hello, World!");:向控制台输出"Hello, World!"。
注意,一份java文件里最多只能有一个public class。
面向对象编程
面向对象意味着程序通过“对象”来组织和运行。而在 Java 中,类(class)是对象的模板,描述了对象的属性和行为。
类中可以包含:
- 字段(field):用来表示对象的数据。
- 方法(method):用来定义对象能做的事。
例子:
1 | class Person { |
而对象有着三个核心特征:
身份:
属性可以发生变化,但身份不会。比如说名字,身份证号等。
状态:
当前所有属性的集合。比如说身高体重等。
行为:
进行会修改当前状态的操作。如吃饭,喝水等。
构造函数
- 是一种特殊方法,与
new联合使用。 - 名字和类名相同,没有返回类型。
- 如果一个类里不写任何构造函数,Java 自动给你生成一个无参的“默认构造函数”。
例子:
1 | class Rational { |
调用:
1 | Rational a = new Rational(3, 4); |
引用/reference
1 | Rational a = new Rational(3, 4); |
b = a;并不是复制一份新对象,只是复制了一份引用地址,即指向同一个对象。所以通过
b改对象,其实就是改a指向的那个对象。
对象作为属性
我们同样也可以将对象设置成属性。(简单来讲就是套娃,对象套对象。)
1 | class Point { |
类属性
private
private 修饰的成员是“仅在本类内部可见”的:类外代码不能直接访问,只能通过本类提供的方法间接使用。
比如说
1 | class Rational { |
1 | Rational a = new Rational(3, 4); |
在其他类里,不能直接通过a.numerator来访问a的分子。
尽量将所有的属性都设置成private。可以更好地保护以及管控对象内的属性。
public
private 修饰的成员是所有类可见。
比如说:
1 | class Rational { |
那么所有类都可以直接调用
1 | Rational a = new Rational(); |
static
static修饰的成员是“类级别”的:所有对象共享一份。
例子:统计创建了多少个 Count 对象:
1 | class Count { |
count是整个类共享的计数器。- 每次
new Count(),构造函数就把当前count值写到info,然后count++。 - 结果:每个对象的
info都是一个唯一的编号 0,1,2,…
相同/相等
==比较的是引用是否相同(是不是同一个对象)。- 想比较两个对象内容是否相同(相等,identical),需要写自己的
equals方法,比如:
1 | public class Rational { |
命名
Sun(Sun Microsystems, Inc.,当时发明Java语言和平台的公司)很早就给 Java 出了一份官方《Code Conventions for the Java Programming Language》,里边明确推荐:
- 类名:
UpperCamelCase→ArrayList,StringBuilder - 方法 / 变量:
lowerCamelCase→loadBefore,userName - 常量(static final):
ALL_CAPS_SNAKE_CASE→MAX_VALUE,DEFAULT_TIMEOUT - 包名:全小写点分 →
java.util,org.example.app
Java 标准库全部遵守这个规范:
ArrayList, HashMap, getClass(), toString(), System.out.println(), Math.max()…… 所有 API 都是驼峰风格。
基本数据类型
Java语言提供了八种基本类型。六种数字类型(四个整数型,两个浮点型),一种字符类型,还有一种布尔型。
byte:
- byte 数据类型是8位、有符号的,以二进制补码表示的整数;
- 最小值是 -2^7;
- 最大值是 2^7-1;
- 默认值是 0;
- byte 类型用在大型数组中节约空间,主要代替整数,因为 byte 变量占用的空间只有 int 类型的四分之一;
- 例子:byte a = 100,byte b = -50。
short:
- short 数据类型是16 位、有符号的以二进制补码表示的整数
- 最小值是 -2^15;
- 最大值是 2^15 - 1;
- Short 数据类型也可以像 byte 那样节省空间。一个short变量是int型变量所占空间的二分之一;
- 默认值是 0;
- 例子:short s = 1000,short r = -20000。
int:
- int 数据类型是32位、有符号的以二进制补码表示的整数;
- 最小值是 -2^31;
- 最大值是 2^31 - 1;
- 一般地整型变量默认为 int 类型;
- 默认值是 0 ;
- 例子:int a = 100000, int b = -200000。
long:
- long 数据类型是64 位、有符号的以二进制补码表示的整数;
- 最小值是 -2^63;
- 最大值是 2^63 -1;
- 这种类型主要使用在需要比较大整数的系统上;
- 默认值是 0L;
- 例子: long a = 100000L,long b = -200000L。
“L”理论上不分大小写,但是若写成”l”容易与数字”1”混淆,不容易分辩。所以最好大写。
float:
- float 数据类型是单精度、32位、符合IEEE 754标准的浮点数;
- float 在储存大型浮点数组的时候可节省内存空间;
- 默认值是 0.0f;
- 浮点数不能用来表示精确的值,如货币;
- 例子:float f1 = 234.5f。
double:
double 数据类型是双精度、64 位、符合 IEEE 754 标准的浮点数;
浮点数的默认类型为 double 类型;
double类型同样不能表示精确的值,如货币;
默认值是 0.0d;
例子:
1
2
3
4
5double d1 = 7D ;
double d2 = 7.;
double d3 = 8.0;
double d4 = 8.D;
double d5 = 12.9867;7 是一个 int 字面量,而 7D,7. 和 8.0 是 double 字面量。
boolean:
- boolean数据类型表示一位的信息;
- 只有两个取值:true 和 false;
- 这种类型只作为一种标志来记录 true/false 情况;
默认值:
- 作为字段/数组元素的话,默认值是
false; - 但如果是局部变量,则没有默认值,需要自己初始化。
- 作为字段/数组元素的话,默认值是
例子:boolean one = true。
char:
- char 类型是一个单一的 16 位 Unicode 字符;
- 最小值是
\u0000(十进制等效值为 0); - 最大值是
\uffff(即为 65535); - char 数据类型可以储存任何字符;
- 例子:char letter = ‘A’;。
除此以外还有一个比较特殊的写法:var,会让编译器从右侧初始化表达式推断变量类型。比如说var n = 7; n 的静态类型是 int。但是无法用var初始化一个变量,即var n;是违规的。
byte、int、long、和short都可以用十进制、16进制以及8进制的方式来表示。
前缀 0 表示 8 进制,而前缀 0x 代表 16 进制, 例如:
1 | int decimal = 100; |
String(字符串)
String 不是基本类型,是一个类,但使用方式比较特殊:
- 字面量:
"Hello World!" - 拼接:
"Hello " + "World"
还有一个非常重要的点:
任意类型在和String做 + 时,会自动转成 String。
例:
1 | double x = -0.55e13; |
但是这是有先后顺序的:在String之前的+运算会被当成普通的加法运算,而String之后的+会被当成字符串拼接,比如说:
1 | System.out.println(1 + 2 + "h" + 1 + 2); |
即先计算了1+2=3,然后再把”3”,”h”,”1”,”2”当成了字符串拼接了起来。
转义字符
Java语言支持一些特殊的转义字符序列。
| 符号 | 字符含义 |
|---|---|
\n |
换行 (0x0a) |
\r |
回车 (0x0d) |
\f |
换页符(0x0c) |
\b |
退格 (0x08) |
\0 |
空字符 (0x0) |
\s |
空格 (0x20) |
\t |
制表符 |
\" |
双引号 |
\' |
单引号 |
\\ |
反斜杠 |
\ddd |
八进制字符 (ddd) |
\uxxxx |
16进制Unicode字符 (xxxx) |
Operation(运算符)
算术运算符
+ - * / %
Java 在二元数值运算里会做二进制数值提升(binary numeric promotion):
- 先把比
int小的整型(byte/short/char)都提升到int; - 再根据两个操作数中“更大的类型”统一到
long/float/double; - 结果类型就是提升后的那个类型。
例子:
1 | int n = 2; |
n提升为long,结果是long,x推断为long,值5L。
1 | int n = 2; |
n提升为double,结果是double,x推断为double,值9.0。
1 | short s1 = 1; |
- 无法成功编译。
s1 + s2先都提升为int,结果是int,不能隐式放回short。
正确写法:short s3 = (short)(s1 + s2);或者var s3 = s1 + s2; // s3 是 int
除法 /
除法会分成整除和浮点除:两个 int/long 做除法得到整除(向零截断),只要有 double/float 参与就是浮点除。
1 | double d1 = 7 / 3; // 7/3 先做整除得 2,再拓宽为 2.0 |
但假设右边的变量都是int,但我们希望左边的结果为double / float时,我们便需要在左边加上(double )/(float)来确保数据类型:
1 | int x = 7, y = 3; |
取余(%)
Java 的余数符号与左操作数(被除数)相同,并满足:a == (a/b)*b + (a%b)(这里的 / 仍是向零截断)。
1 | int v1 = 11 % 4; // 3 |
自增/自减(++/--)
前缀:先改值后取值;后缀:先取值后改值。
1 | int n = 5; |
但是注意,有一个容易出错的点是:
1 | int a = 0; |
因为a = a++;相当于给a重新又赋值成了0,没有++的机会。
1 | double d = 3.14; |
比较运算符
基本值比较
1 | boolean b1 = 4 == 4.0; // true(4 提升为 4.0) |
引用比较(对象)
1 | class A { |
==比较的是引用是否同一对象,不是内容。若想按内容比较,应覆写equals。
字符串相等性
1 | String s1 = "abc"; |
- 结论:比较字符串内容用
equals,不要用==。
浮点比较陷阱
1 | double d = Math.sqrt(2) * Math.sqrt(2); |
解决:用误差容忍(epsilon):
1
boolean close = Math.abs(d - 2.0) < 1e-10;
逻辑运算符
真值表
|(逻辑或,不短路):false|false => falsefalse|true => truetrue |false => truetrue |true => true
^(逻辑异或,不短路):两边不同为truefalse^false => falsefalse^true => truetrue ^false => truetrue ^true => false
(补充:&、| 有布尔版(不短路)与按位版;&&、|| 是短路逻辑。)
短路与副作用
1 | int n1 = 7; |
赋值运算符与结合性
所有赋值运算符(=、+=、-=、...)都是右结合:从右往左算。+= 等复合赋值在需要时会隐式强制类型转换(先算出右值,再转换为左侧变量类型)。
1 | int n1 = 1, n2 = 2, n3 = 3; |
1 | int n1 = 1, n2 = 2, n3 = 3; |
1 | int n1 = 1, n2 = 2, n3 = 3; |
- 原因:
n2 + n3不是变量,不能作为赋值左值。
1 | int n1 = 1, n2 = 2, n3 = 3; |
修饰符
Java语言提供了很多修饰符,主要分为以下两类:
- 访问修饰符
- 非访问修饰符
修饰符用来定义类、方法或者变量,通常放在语句的最前端。我们通过下面的例子来说明:
1 | public class ClassName { |
访问控制修饰符
Java中,可以使用访问控制符来保护对类、变量、方法和构造方法的访问。Java 支持 4 种不同的访问权限。
- default (即默认,什么也不写): 在同一包内可见,不使用任何修饰符。使用对象:类、接口、变量、方法。
- private : 在同一类内可见。使用对象:变量、方法。 注意:不能修饰类(外部类)
- public : 对所有类可见。使用对象:类、接口、变量、方法
- protected : 对同一包内的类和所有子类可见。使用对象:变量、方法。 注意:不能修饰类(外部类)。
访问控制:
| 修饰符 | 当前类 | 同一包内 | 子孙类(同一包) | 子孙类(不同包) | 其他包 |
|---|---|---|---|---|---|
public |
Y | Y | Y | Y | Y |
protected |
Y | Y | Y | Y/N | N |
default |
Y | Y | Y | N | N |
private |
Y | N | N | N | N |
注释
单行注释:
1 | // 注释 |
多行注释:
多行注释以 /*开始,以*/结束:
1 | /* |
文档注释:
文档注释以 /** 开始,以 */ 结束
1 | /** |
测试
JUnit5是Java领域里标准单元测试框架。
import:
1 | import org.junit.jupiter.api.Test; |
先来看一个简单的例子:
1 |
|
@Test是一个 注解(annotation),来自 JUnit(比如 org.junit.Test)。它告诉测试框架:“下面这个方法是一个测试用例,请在执行测试时自动运行它”。 只要点 IDE 里的 “Run Tests”,测试框架就会扫描所有带 @Test 的方法,然后一个个执行。
常用注解包括:
@Test: 标记一个方法为单元测试方法。@BeforeEach: 前置设置。在每个测试方法运行之前执行一次,用于初始化数据或环境。@AfterEach: 后置清理。在每个测试方法运行之后执行一次,用于清理资源。@ParameterizedTest: 参数化测试。允许使用不同的输入数据多次运行同一个测试方法,减少重复代码。
assertEquals(42, 42);是一个断言 (Assertions),是测试的核心。它用来验证实际运行结果是否符合预期。
常用断言包括:
- 相等性与不等性断言 (Equality)
assertEquals(expected, actual): 断言期望值与实际值相等(比较内容/值)。assertNotEquals(unexpected, actual): 断言实际值与给定的值不相等。assertArrayEquals(expected, actual): 断言两个数组包含相同的元素序列且顺序一致。
- 真值断言 (Boolean Conditions)
assertTrue(condition): 断言给定的布尔条件为 真 (true)。assertFalse(condition): 断言给定的布尔条件为 假 (false)。
- 空值断言 (Nullity)
assertNull(actual): 断言实际值为 空 (null)。assertNotNull(actual): 断言实际值 非空。
- 对象身份断言 (Identity / Same Reference)
assertSame(expected, actual): 断言期望对象和实际对象是同一个对象实例(即引用相等)。assertNotSame(unexpected, actual): 断言两个对象不是同一个对象实例。
- 异常与行为断言 (Exceptions and Behavior)
assertThrows(Type, executable): 断言在执行可执行代码时,会抛出指定类型的异常。assertDoesNotThrow(executable): 断言在执行代码时,不会抛出任何异常。assertTimeout(duration, executable): 断言代码块在指定的时间内执行完毕(非抢占式)。assertTimeoutPreemptively(duration, executable): 断言代码块在指定时间后立即被中止(抢占式)。
- 组合与失败断言 (Grouping and Failure)
assertAll(executables...): 组合断言。即使前面的断言失败,也会继续执行所有断言,然后统一报告所有失败。fail(message): 强制使当前测试方法失败,并带有一个可选的消息。
除此以外,Java 测试方法通常有几个特点:
- 必须是
public
这样测试框架可以通过反射来调用这个方法。 - 返回类型是
void
测试的“结果”不是通过返回值表示的,而是:- 不抛异常 → 视为测试通过
- 抛出断言异常(AssertionError)或其他异常 → 视为测试失败
控制结构
控制结构一般分为3种:
- 顺序结构
- 选择结构
- 迭代结构
任何可计算的函数都可以通过顺序、选择和迭代这三种结构计算出来(图灵完备性) 。
选择结构
if / else
1 | int score = 85; |
三元运算符 ? :
1 | int x_abs = x >= 0 ? x : -x; |
如果问号?前面的条件满足,则走冒号:前的分支,反之则走冒号:后面的分支。
switch(适合离散值分支)
最基础的写法,使用冒号 : 来标记分支。
使用
case 值:来定义入口。必须使用
break;:执行完代码后,必须显式调用break语句来跳出switch块 。穿透现象 (Fall-through):如果忘记写
break,程序会继续向下执行下一个case的代码,这通常会导致逻辑错误(但也可能被故意利用) 。
1 | switch (monat) { |
而在Java 14中引入了一种新的改进写法(非常好用):
使用
case 值 -> 语句;的形式。无需
break:执行完箭头后的语句会自动跳出switch,不会发生穿透,避免了传统写法中最容易出现的错误 。支持多值匹配:可以在一个
case中用逗号分隔多个值,例如case 1, 3, 5 -> ...。
例子:
1 | int tageImMonat(int monat) { |
switch 不仅可以执行动作,还可以直接返回值(作为表达式赋值给变量) 。
写法 A(使用箭头): 直接返回箭头后的值。
1
2
3
4
5String season = switch (month) {
case 12, 1, 2 -> "winter";
case 3, 4, 5 -> "spring";
// ...
};写法 B(使用冒号 + yield): 如果在表达式中仍使用传统的冒号写法(例如为了执行代码块),则必须使用
yield关键字来返回值 。1
2
3
4
5String season = switch (month) {
case 12, 1, 2:
yield "Winter"; // 使用 yield 返回
// ...
};
迭代结构
for
1 | for (int i = 0; i < n; i++) { |
这种写法i会遍历[0,n)的所有数。
如果需要遍历时也需要考虑n的情况,可以写成
1 | for (int i = 0; i <= n; i++) { |
会比较直观。
注意,循环的每一轮的执行顺序是这样的:
- 先判断条件:
i < n - 条件为真就执行循环体:
System.out.println(i); - 然后再执行更新表达式:
i++ - 回到 1)
1 | int[] arr = {1,2,3}; //定义数组 |
while
1 | int i = 3; |
先判断条件,若为真则执行循环体,执行完后再次判断;若为假则跳过 。
- 可以用
break来退出当前循环 - 也可以用
continue跳过当前循环的剩余部分并直接开始下一轮循环
do-while
1 | int x = 0; |
至少执行一次循环体,因为条件检查在末尾 。
数组 Array
基础
定义: 数组将同类型数据连续存储,通过索引(Index)访问,索引从0开始 。
声明/创建/初始化:
1 | // 声明 |
例子:
1 | int [] vector; |
引用语义:
数组变量(如
a)存储的不是数组本身,而是一个指向数组的引用(Reference) 。别名现象 (Aliasing): 执行
int[] b = a;后,b和a指向同一个内存地址。修改b[i]会导致a[i]也发生变化 。
操作
长度: name.length 获取数组元素个数 。
例子:
1 | int [] vector = {1,2,3,4}; |
越界: 访问范围之外的索引会触发 ArrayIndexOutOfBoundsException 。
遍历 (Iteration):
通常写法:
1 | for (int i = 0; i < a.length ; i++){ |
1 | for(int i: a){ |
也可以用while:
1 | int i = 1; |
遍历数组的值:
1 | int idx = 0; |
数组复制:
- 直接赋值 (
b=a) 只是复制引用。 - 若要深拷贝(真正复制内容),必须创建一个新数组并循环赋值
b[i] = a[i]。 - 也可以使用
java.lang.System.arraycopy(...)。
1 | int [] a = {1,2,3,4}; |
例子
查找元素
查找是否存在
1 | boolean has (long[a], long x){ |
如果存在,查找index:
1 | boolean has (long[a], long x){ |
排序
Bubble Sort:
1 | public static void bubbleSort(int[] fish) { |
多维数组
java仅直接支持一维数组。二维数组实际上是元素维数组的一个数组。
1 | new int[][] twoDimArray; |
1 | A = new int [n][m] |
当然,二维数组不一定每行的长度都是一样的,比如说
1 | new int[][] {{1, 3}, {25}, {7, 4, 6, 9}} |
也是合法的。
例子(向量加法):
(假设a,b的长度一样且不等于0)
1 | public static int[] addVector(int[] a, int[] b){ |
例子(点积):
(假设a,b的长度一样且不等于0)
1 | public static int scalarProduct(int [] a, int [] b){ |
例子(矩阵乘法):
1 | public static int[][] matrixMult(int[][] matrixA, int[][] matrixB) { |
数据结构
链表
构造函数:
1 | public class List{ |
插入(将新元素插入到当前元素的后面):
1 | public void insert (int x){ |
相当于可以拆成2步:
new List(x,next);:新创建一个List元素,并将其next指针的内容设置为当前位置的next指针里的内容,然后next =:将当前的next指针修改成指向这个新创建的List元素的指针
删除(下一个元素):
1 | public void delete (){ |
toString:
1 | pubblic String toString (){ |
判断是否为空:
1 | public static boolean isEmpty (List l){ |
计算长度:
1 | private int length(){ |
(与数组之间的)转换:
1 | public static List arrayToList (int [] a){ |
Mergesort
1 | public static List merge (List a, List b) { |
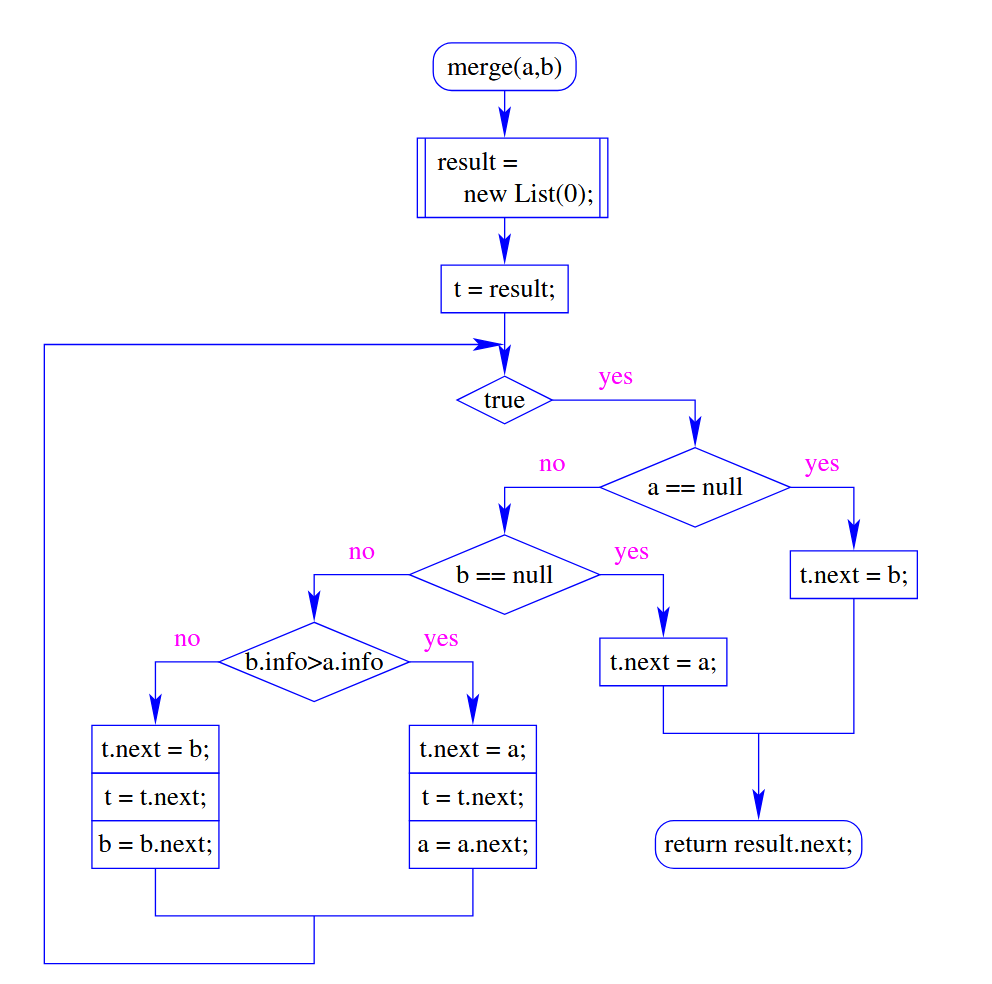
栈/Stack (Last In First Out)
1. 实现思路一:使用链表 (List)
1 | public class Stack { |
2. 实现思路二:使用动态数组 (int[])
1 | public class Stack { |
pop的优化版本:
1 | public int pop() { |
Queue(First In First Out)
1. 实现思路一:使用链表 (List)
使用两个指针 first(队首)和 last(队尾)来维护队列。
1 | public class Queue { |
操作:
1 | // 出队元素(Dequeue) |
2. 实现思路二:使用动态数组(环形队列)
使用数组和索引指针 first(队首索引)和 last(队尾索引),并通过模运算实现环形队列,并支持动态扩容。
1 | public class Queue { |
操作:
1 | // 入队元素(Enqueue) |
另一种完整的List/Stack/Queue的实现
List部分:
1 | package pgdp.collections; |
Stack:
1 | package pgdp.collections; |
Queue:
1 | package pgdp.collections; |
LinkedList(链表)
创建与复制
1 | import java.util.*; |
判空与长度
1 | a.isEmpty(); // 是否为空 |
增加元素(头/尾/指定位置)
1 | a.add(10); // 尾部追加(返回boolean) |
访问元素(不删除)
1 | a.get(0); // 按索引访问(O(n)),空则返回 NoSuchElementException |
删除元素(并返回)
1 | a.removeFirst(); // 删除并返回头元素(空会抛异常) |
删除指定元素/位置
1 | a.remove(0); // 删除索引0处元素,返回被删元素 |
查找/判断包含
1 | a.contains(10); // 是否包含 |
遍历
1 | for (int x : a) { ... } // 增强 for |
批量操作
1 | a.addAll(b); // 把 b 全部追加到 a |
转换与打印
1 | System.out.println(a); // 直接打印:[1, 2, 3] |
ArrayList(动态数组)
创建与初始化
1 | import java.util.*; |
添加元素
1 | a.add(10); // 末尾追加 |
读取与改
1 | int x = a.get(0); // 按索引读(ArrayList 很快) |
删除
按索引删除
1 | a.remove(0); // 删除索引0,返回被删元素 |
按值删除(注意 Integer 的坑)
1 | a.remove(Integer.valueOf(10)); // 删除“值为10”的第一个匹配,返回 boolean |
批量删除/保留
1 | a.clear(); // 清空 |
查找与判断
1 | a.size(); |
遍历
1 | for (int v : a) { ... } |
排序与反转
1 | Collections.sort(a); // 升序 |
截取子列表
1 | List<Integer> sub = a.subList(1, 4); // [1,4) 左闭右开 |
subList 返回的是原列表的视图,改 sub 会影响 a,反之也一样。想要独立拷贝:
1 | List<Integer> subCopy = new ArrayList<>(a.subList(1, 4)); |
转换
1 | Object[] arr = a.toArray(); |
面向对象
继承(Vererbung)
现实世界里有很多相似但不完全相同的对象,比如说人类,猩猩,狼等哺乳类动物。
Idea:
- 把共同点提到上面(父类 / 超类)
- 把不同点留在下面(子类 / 派生类)
- 这样可以 增量开发 和 复用代码(software reuse)
来看个很简单的例子:书和字典。
因为所有书都有页数这个属性,所有我们可以把这个属性直接放进书(父类)的字段里,这样一来各种书都会自动继承这个字段,不需要我们在每种不同的书里都再定义一遍它。
书(父类):
1 | public class Book { |
字典(子类):
1 | public class Dictionary extends Book { |
extends 表示继承:子类Dictionary拥有 Book的所有字段(attribute),再加上自己的字段。
访问控制(private / protected / public)
| 修饰符 | 同类内部 | 同 package | 子类 | 外部世界 |
|---|---|---|---|---|
private |
✅ | ❌ | ❌ | ❌ |
| default(不写) | ✅ | ✅ | (同 package 的子类才行) | ❌ |
protected |
✅ | ✅ | ✅ | ❌ |
public |
✅ | ✅ | ✅ | ✅ |
1 | public class Book { |
例子:
1 | public class Food { |
1 | public class Pizza extends Food { |
1 | public class Eating { |
Pizza继承了Food的所有成员,但calories()和属性都是private,所以在Pizza里不能直接访问。但可以通过public的方法calories_per_serving() 间接使用。
关键字 super
很多时候我们需要在子类的构造器里调用父类的构造器,这个时候就需要用到super()。
比如说刚才披萨例子里的:
1 | public Pizza (int amount_fat) { |
调用super()相当于就是在调用父类的构造器,所以接收的参数也一模一样。
而super和this类似,只不过指代的是父类。可以用super.来调用父类的所有函数。
比如说刚才字典的例子可以改写成这样:
1 | public class Book { |
1 | public class Dictionary extends Book { |
属性和方法的覆盖/重写与隐藏
方法重写(override)
当子类里定义了一个同名、同参数列表、同返回类型的方法,就会覆盖(verschatten)父类的实现。
方法调用解析的规则:
- 编译时,先在静态类型的类中根据方法名和参数类型,找到最合适的签名(考虑重载)。
- 运行时,从动态类型开始往上找这个签名的方法,实现采用最下面的那个实现。
所以方法的选择是参数,静态类型和动态类型共同决定的。
Object 类
任意类如果没写 extends,默认都是 extends Object
Object 提供了很多通用方法,其中常用的:
String toString():把对象转成字符串boolean equals(Object obj):默认比较引用是否相同(this == obj)int hashCode():给对象一个哈希值,和集合类有关
例子:
1 | public class Poly { |
抽象类(abstract)、final 类和接口(interface)
抽象方法与抽象类
抽象方法:没有实现,只写方法头,用abstract标记。需要在子类里具体实现。
抽象类:只要含有抽象方法,这个类本身也必须标记abstract,不能直接new。不过一个抽象类里也可以有具体的方法。(比如下面例子里的getValue())
例子:
1 | public abstract class Expression { |
不同的子类(每个里都需要具体实现evaluate()):
1 | public final class Const extends Expression { |
1 | Expression e = new Add( |
final类和final方法
与abstract通常需要子类来实现其抽象方法后才能真正使用不同,final是不能有子类。
final class:不能有子类。(例如上面的Const,Add,Neg)final方法:不能被子类重写。final变量:只能赋值一次(常量)。
接口(Interfaces)
之前说到了一个类可以有很多的子类,但是如果我们希望一个子类C同时继承A类和B类的话,那么当A,B里都有一个相同名字的函数meth()时,C类调用super.meth()时到底会调用A类的还是B类的呢?
Java的解决方案非常简单:只允许单继承类,但允许实现多个接口。
接口可以看作是一个特殊的抽象类,只不过其中:
- 所有方法都是抽象的
- 所有字段都是常量
接口这个东西有点抽象,所以我们先来看个简单的例子:1
2
3public interface Shape {
double area();
}
1 | // 圆形 |
1 | public class Main { |
1 | public static double totalArea(Shape[] shapes) { |
这里的接口主要有几个好处:
- 提供统一的类型(Shape),从而可以写通用代码:函数参数/返回值/集合元素都用接口类型,不依赖具体类。
- 处理混合类型集合更简单:
Shape[] / List<Shape>里放各种形状,直接循环调用area(),无需instanceof。 - 编译期强制规范:
implements Shape的类必须实现area(),编译器自动检查,减少约定没遵守的错误。
当然接口之间也可以extends:
例如接口 Countable:
1 | public interface Comparable { |
1 | public interface Countable extends Comparable, Cloneable { |
Countable组合了两个接口:Comparable和Cloneable,任何实现Countable的类都必须实现这三个接口中的所有方法(compareTo, next, prev, number 等)。
多态(Polymorphie)
Polymorphie这个单词来自希腊语词根:
- poly- = 多、许多
- -morph = 形态、形式
- -ie(名词后缀)
所以字面意思就是:多种形态/多种形式性。
而在面都对象编程里的定义一般是这样:
多态:同一个“接口/父类型”的变量或方法调用,在运行时可以指向不同的具体对象,从而表现出不同的具体行为。
简单来讲就是:同一句代码(同一个方法调用),因为对象的真实类型不同,执行出不同的结果。
分为编译期和运行期。编译期会检查函数签名,运行期会调用具体的最底层的函数实现。
在继承体系中的多态与方法选择规则
泛型类(Generische Klassen)
可以用java自带的LinkedList<>以及泛型来实现Stack:
1 | package pgdp.collections; |
这里<>里的T只是一个占位符,一般用T是因为取的Type的首字母。可以用任意字母。
包装类(Wrapper-Klassen)
递归
Fibonacci
普通递归:
1 | public static long fibonacciRec(int n) { |
尾递归:
1 | public class Fibonacci { |
异常处理
当程序运行出现错误时,会中断正常执行流程 ,然后创建并抛出(throw)一个错误/异常对象。
我们可以捕获并处理这些异常。
所有的错误都继承自 Throwable 类。主要分为两类 :
Error:致命错误,通常导致程序终止。- 例子:
StackOverflowError(栈溢出,通常由无限递归引起)、OutOfMemoryError(内存耗尽)。 - 处理建议:应用程序通常不应该试图捕获这些错误,因为一旦发生,程序基本就无法继续运行了。
- 例子:
Exception:可处理的异常。- a. 运行时异常 (Runtime Exceptions / Unchecked Exceptions):
- 继承自
RuntimeException。 - 特点:通常由编程逻辑错误引起。编译器不强制要求你捕获它们。
- 例子:
NullPointerException:试图访问空对象的属性或方法。IndexOutOfBoundsException:访问数组或列表越界。ArithmeticException:如除以零(例如1/0)。
- 继承自
- b. 受检异常 (Checked Exceptions):
- 继承自
Exception但不是RuntimeException的子类。 - 特点:通常由外部环境引起(如文件不存在、网络断开)。编译器强制要求你必须处理(捕获或声明抛出),否则代码无法编译通过。
- 例子:
IOException(输入输出错误)、FileNotFoundException(文件未找到)。
- 继承自
- a. 运行时异常 (Runtime Exceptions / Unchecked Exceptions):
事先定义好的错误类型:
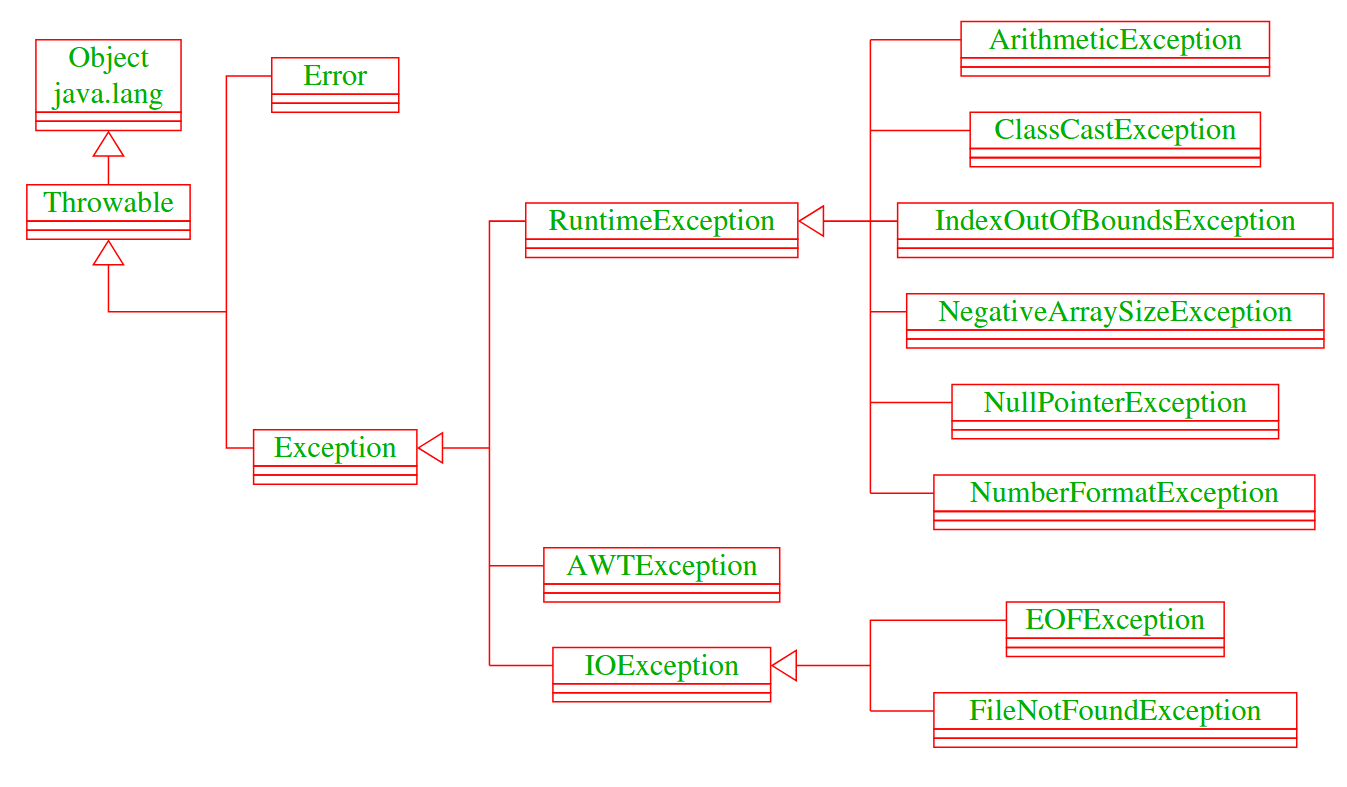
IOException:“输入/输出异常”(Input/Output Exception)FileNotFoundException- 读文件时路径不存在
- 没权限访问
- 给了一个目录当文件去打开
EOFExceptionEOF = End Of File(文件结束)。
通常出现在用DataInputStream/ObjectInputStream之类按“二进制格式”读数据时,读到文件末尾还想继续读。InterruptedIOExceptionI/O 操作被中断,或超时导致读写中断。常见于网络流、某些阻塞读写。
UnsupportedEncodingException:某种字符编码不支持。
RuntimeException
如果不处理会怎样?
如果错误发生且未被捕获,程序执行会中止 。
比如说在这个例子里:
1 | public class Zero { |
程序崩溃并打印堆栈跟踪(Stack Trace):
1 | Exception in thread "main" java.lang.ArithmeticException: / by zero |
包含三部分信息 :
- 发生错误的线程(如
main)。 - 错误类的名称及消息(如
java.lang.ArithmeticException: / by zero)。 - 发生错误的位置(调用栈信息) 。
处理错误
错误处理的标准结构:
try块:- 包含可能出错的代码语句 。
catch块:紧跟在
try之后,包含错误处理逻辑。形式为catch (Exc e) {...},其中Exc是错误类型,e是错误对象 。多重捕获:可以有多个
catch块。- 注意顺序:必须先捕获具体的子类异常,再捕获通用的父类异常(如先
catch (FileNotFoundException e),后catch (IOException e))。如果顺序反了,子类的catch块永远无法到达。
finally块:无论是否发生异常,
finally中的代码一定会被执行。- 如果
try块无错误:try执行完后执行finally。 - 如果捕获了错误:
catch块执行完后执行finally。 - 如果错误未被捕获:先执行
finally,然后继续抛出错误 。
- 如果
用途:主要用于资源清理,如关闭打开的文件流(
stream.close())、释放数据库连接等。哪怕try块中有return语句,finally也会在返回之前执行。
自定义异常
自定义异常的过程主要分为三步:继承、构造、抛出。
1. 选择继承的父类 (核心决策)
这是定义异常时最重要的第一步。你需要决定你的异常是“受检的”还是“非受检的”。
- 情况 A:继承
java.lang.Exception(受检异常 Checked Exception)- 含义:这是一个必须被处理的错误。
- 场景:通常用于业务逻辑错误或外部环境问题(如“余额不足”、“用户不存在”)。你希望强制调用者显式地处理这个情况(try-catch)。
- 后果:如果不捕获,代码无法编译通过。
- 情况 B:继承
java.lang.RuntimeException(非受检异常 Unchecked Exception)- 含义:这是一个编程错误或不可恢复的错误。
- 场景:通常用于参数错误或代码逻辑漏洞。
- 后果:编译器不强制要求捕获。
2. 提供构造函数
为了让异常携带错误信息,你需要在你的类中重写构造函数,并调用父类(super)的方法。
Java
1 | // 示例:定义一个“库存不足”异常(受检异常) |
3. 抛出与声明 (Throw & Throws)
定义好之后,你就可以在业务代码中使用它了。
抛出 (Throw):在检测到错误逻辑的地方,创建一个异常对象并抛出。
Java
1
2
3if (quantity > stock) {
throw new OutOfStockException("当前库存不足,剩余: " + stock);
}声明 (Throws):如果你定义的异常继承自
Exception(受检异常),你必须在方法签名上告诉调用者可能会抛出这个异常。Java
1
2
3public void buyProduct(int quantity) throws OutOfStockException {
// ...
}
为什么需要异常
核心的原因是为了把“正常逻辑”与“错误处理”分开。
比如说下面这个例子
用 if 的代码风格:
1 | if (打开文件成功) { |
写起来也很麻烦,阅读起来非常累,很难一眼看清核心业务到底在干嘛。
用 try-catch 的代码风格:
1 | try { |
这种写法让人一眼就能看懂“正常情况下程序在做什么”。
除此以外,很多错误是检查不出来的 (不可预测性)。有些错误是外部环境导致的,if 检查在时间上存在漏洞(这叫做 TOCTOU 问题:Time Of Check to Time Of Use)。
字符串 (Strings)
在JAVA中,String 是一个非常特殊且极其重要的类。
不可变性 (Immutability)
一个String对象一旦在内存中被创建,它的内容就永远无法改变。
例子:
1 | String s = "Hello"; |
看起来 s 变了,但实际上:
- 内存中创建了”Hello”。
- 内存中创建了” World”。
- 内存中创建了一个全新的对象”Hello World”。
- 变量
s的指针从指向”Hello”改为指向”Hello World”。 - 原来的”Hello”如果没人用,就会变成垃圾被回收。
为什么这么设计?
- 安全性:String 常用于数据库连接、文件名、网络地址。如果它是可变的,黑客可以在你检查完权限后、真正使用前修改它的内容。
- 缓存:因为不可变,所以它的哈希值(HashCode)只需要算一次就可以缓存起来,放入 HashMap 效率极高。
- 线程安全:多个线程同时读一个字符串,完全不用担心有人会改动它。
字符串常量池 (String Pool)
为了避免内存浪费(比如代码里写了 100 次 “Hello”,没必要在内存里存 100 份),Java 设计了一个特殊的内存区域叫 String Pool。
两种创建方式:
字面量赋值 (Literal)
1
2String s1 = "Hallo";
String s2 = "Hallo";Java 会先去池子里找有没有 “Hallo”。
- 如果没有:创建一个放入池子,返回引用。
- 如果有:直接返回池子里那个对象的引用。
结果:
s1 == s2为 true (它们指向同一个内存地址)。使用
new关键字1
String s3 = new String("Hallo");
new关键字强制在堆内存 (Heap) 中创建一个新对象,不管池子里有没有。结果:
s1 == s3为 false (地址不同)。
intern() 方法
它是连接“普通堆内存”和“字符串池”的桥梁。
作用:手动将字符串加入池中。
逻辑: 调用
s3.intern()时:- 检查池中是否已经包含等于
s3的字符串。 - 如果有:返回池中那个对象的引用。
- 如果没有:将
s3的引用加入池中,并返回它。
- 检查池中是否已经包含等于
代码演示:
1
2
3
4
5
6String s3 = new String("Hallo"); // s3 在堆上,不在池里
String s4 = s3.intern(); // s4 指向池里的 "Hallo"
String s1 = "Hallo"; // s1 也是池里的 "Hallo"
System.out.println(s3 == s1); // false
System.out.println(s4 == s1); // true
字符串比较
==:比较的是内存地址(是不是同一个对象)。- 利用String Pool和
intern(),我们可以强制让相同内容的字符串共享同一个对象,从而可以使用==来加速比较(比逐个字符对比快得多)。
- 利用String Pool和
equals():比较的是内容(长得一不一样)。
这个String Pool本质上是通过哈希表来实现高效运作的:
- 计算字符串内容的哈希值
- 分配到指定的桶里
- 查找的时候先计算哈希值,然后去桶里找
常用的String方法
trim()
用法:
1 | String s2 = s1.trim(); |
作用:
- 去掉字符串开头和结尾的所有空白字符(包括空格、制表符
\t、换行\n等)。 - 中间的空格不会被去掉。
- 返回新字符串,不会直接修改原本的。
例子:
1 | String s = " hello world \n"; |
isEmpty()
用法:
1 | boolean b = s.isEmpty(); |
作用:
- 判断字符串长度是否为 0,相当于
s.length() == 0。
例子:
1 | "".isEmpty(); // true |
toLowerCase()
用法:
1 | String lower = s.toLowerCase(); |
作用:
- 返回一个全部小写的新字符串,不改变原来的字符串。
例子:
1 | "PiNguin".toLowerCase(); // "pinguin" |
replace(target, replacement)
用法:
1 | String s2 = s1.replace(".", ""); |
作用:
- 把所有出现的子串
target替换成replacement。 - 不用正则,就是普通的字符串匹配。
- 返回新字符串,不改原来的。
例子:
1 | String s = "Pinguin, Pinguin! (?Ping(uin!)"; |
split(String regex)
用法:
1 | String[] parts = s.split("\\s+"); |
作用:
- 用参数
regex作为正则表达式,将字符串按匹配的位置拆分成若干段,返回String[]。 - 注意:参数是正则表达式而不是普通字符串。
\\s+实际上就是\s+,表示匹配一个或多个空白字符(空格、tab、换行等)。
split(" ")则会按单个空格拆分。
例子:
1 | String s = " hello world \n pinguin "; |
length()
用法:
1 | int len = s.length(); |
作用:
- 返回字符串中字符的个数(不是字节数)。
例子:
1 | "".length(); // 0 |
compareTo()
用法:
1 | int result = s1.compareTo(s2); |
作用:
- 按字典序(lexicographical order)比较两个字符串的大小。
- 返回一个
int(只保证小于等于大于0这三种情况,不保证具体的数值。):< 0:s1在字典序上 小于s2= 0:s1和s2内容相同> 0:s1在字典序上 大于s2
例子:
1 | "abc".compareTo("abd"); // 结果 < 0,因为 'c' < 'd' |
迭代器 (Iterators)
如果在编程中没有迭代器,我们处理不同的数据结构会非常麻烦:数组用索引 i 遍历,链表用 node.next 遍历,哈希表(Set/Map)甚至没有顺序,很难遍历。
迭代器模式 (Iterator Pattern) 的核心目的就是:提供一种统一、标准的方式来遍历任何类型的集合,而不需要了解集合底层的具体实现(是数组还是链表)。
在 Java 中,迭代器机制涉及两个长得很像但职责完全不同的接口:
Iterable<T>(可迭代的)角色:这是集合(容器)要实现的接口。
含义:它向外界声明:“我是存储数据的容器,你可以遍历我。”
核心方法:
iterator(): 这个方法被调用时,必须返回一个新的、准备好从头开始遍历的Iterator对象。
地位:所有的标准集合(List, Set 等)都实现了这个接口。
Iterator<T>(迭代器)角色:这是负责执行遍历操作的“指针”对象。
含义:它不存储数据,它只是记录“当前读到哪里了”。
核心方法:
boolean hasNext():- 探测。检查是否还有下一个元素。如果还没遍历完,返回
true。
- 探测。检查是否还有下一个元素。如果还没遍历完,返回
E next():- 取值并前移。返回当前的元素,并将内部指针向下移动一步。
- 注意:如果已经没有元素了还强行调用
next(),会抛出NoSuchElementException。
void remove()(可选):- 删除。删除最近一次由
next()返回的那个元素。 - 注意:不能连续调用两次
remove(),必须先调用next()才能调用remove()。
- 删除。删除最近一次由
例子:
1 | class IterableString implements Iterable<Character> { |
1 | class IterableStringIterator implements Iterator<Character> { |
Kollektionen (集合框架)
Collection 是对象的容器(Sammlung von Objekten)。
目标:
- 统一架构:提供一套标准的方式来存储和操作数据,不需要程序员自己去写链表或动态数组。
- 抽象化:你只需要针对接口(如
List)编程,而不需要关心底层是用数组实现的(ArrayList)还是链表实现的(LinkedList)。 - 互操作性:不同的库可以轻松交换数据。
- 性能:Java 官方提供了高性能的实现。
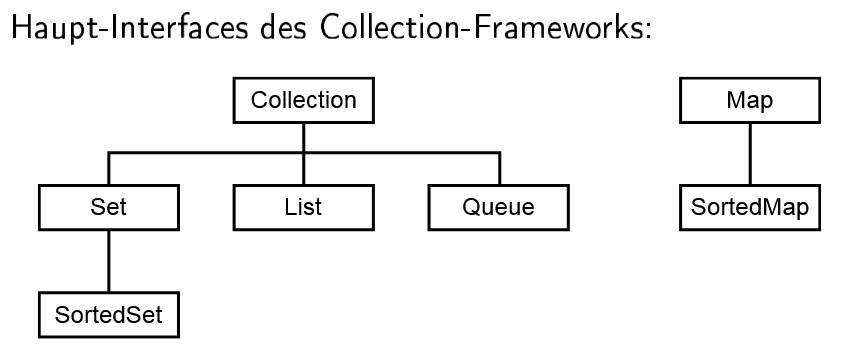
Collection<E> 接口
这是最通用的接口。如果你只知道一个东西是 Collection:
- 你知道的:它能添加(
add)、删除(remove)、查大小(size)、清空(clear)、检查包含(contains)、转数组(toArray),并且它是Iterable的(可以用 for-each 循环)。 - 你不知道的:它是否有序?是否允许重复?是否允许 null?(这些取决于具体的子接口或实现类)。
List<E> 接口
- 特点:
- 有序(Geordnete Collection)。
- 允许重复(Duplikate erlaubt)。
- 支持通过 索引 (Index) 访问元素(如
get(int index))。
- 常用实现类:
ArrayList:基于动态数组,查询快,增删慢。LinkedList:基于链表,增删快,查询慢。
Map<K, V> 接口
- 特点:
- 模拟数学中的函数映射。
- 存储 Key-Value (键值对)。
- Key 不允许重复(每个 Key 最多映射到一个 Value)。
- 核心方法:
put(K key, V value): 存入数据。get(Object key): 根据键取值。keySet(): 返回所有键的集合(是一个Set)。values(): 返回所有值的集合(是一个Collection)。
Collections 工具类 (Algorithms)
Collections 类包含了一堆静态方法,用来操作集合 :
sort(List): 对列表进行排序。reverse(List): 反转列表顺序。disjoint(c1, c2): 检查两个集合是否没有交集(完全不相关)。frequency(c, o): 统计元素o在集合c中出现的次数。replaceAll(list, old, new): 批量替换。
Lambda 表达式与流(Streams)
Lambda 表达式
在 Lambda 出现之前,如果我们想把一段“逻辑”当作参数传递给方法(比如定义排序规则),我们必须创建一个匿名内部类。这通常意味着要写 5-6 行代码,而其中真正有用的逻辑只有 1 行。
Lambda表达式旨在消除这种“样板代码” (Boilerplate Code)。
语法结构
Lambda 本质上是一个匿名函数(没有名字的方法)。
- 语法:
(参数列表) -> { 方法体 } - 示例:
- 无参数:
() -> System.out.println("Hi") - 有参数:
(x) -> x * x - 多行逻辑:
(x, y) -> { int sum = x + y; return sum; } () -> {... ; ...}
- 无参数:
注意,写多行逻辑时必须要用{}把要执行的逻辑包起来,否则会报错。
例子:
匿名内部类:
1
2
3
4
5
6Collections.sort(list, new Comparator<String>() {
public int compare(String s1, String s2) {
return s1.compareTo(s2);
}
});Lambda 表达式:
1
2// 编译器会自动推断 s1 和 s2 的类型
Collections.sort(list, (s1, s2) -> s1.compareTo(s2));
Lambda 表达式只能用于函数式接口,即只包含一个抽象方法的接口。
方法引用
方法引用(method reference),是 lambda 的一种简写形式。
例子:
我们想对每个元素调用String.valueOf函数:
1 | x -> String.valueOf(x) |
那么我们可以直接简写成这样:
1 | String::valueOf |
流 API (Streams)
什么是 Stream?
- 它不是数据结构(不像 List 或 Set 那样存储数据)。
- 它是对数据源(集合、数组)进行操作的管道 (Pipeline)。
- 核心思想:你可以像工厂流水线一样,对数据进行一系列的加工处理。
使用 Stream 的标准步骤:
- 创建流 (Source):从数据源生成流。
list.stream()
- 中间操作 (Intermediate Operations):对数据进行处理,惰性执行 (Lazy)。
- 这些操作返回的还是一个 Stream,所以可以链式调用。
- 终止操作 (Terminal Operations):触发流的执行,并产生最终结果。
- 这步之后,流就关闭了,不能再用了。
stream的函数的参数里可以直接写Lambda表达式,非常方便。
常用的 Stream 操作
创建:
Stream.of(a, b, c)
少量固定元素(对象类型)。1
Stream.of(one, two, three)
Arrays.stream(array)
从数组创建。对象数组 →Stream<T>;基本类型数组 →IntStream/LongStream/DoubleStream。1
2Arrays.stream(caughtFish)
Arrays.stream(intArray) // IntStreamcollection.stream()
从集合创建(顺序取决于集合类型)。1
caughtFish.stream()
Stream.generate(supplier)
无限流,按需调用supplier.get()生成元素(通常要配limit)。1
Stream.generate(supplier).limit(100)
(常见补充)
Stream.iterate(seed, next)
按规则生成序列(也常是无限)。1
Stream.iterate(0, x -> x + 1).limit(10)
中间操作:
变换 / 映射
map(f):每个元素变成另一个元素(x 变成f(x) )1
2.map(x -> x * x)
.map(String::valueOf)flatMap(f):一个元素变成“多个元素的 Stream”(1→多),再铺平1
.flatMap(fish -> Arrays.stream(birthHelper(fish)))
mapToInt:将Stream转成IntStream
mapToLong:将Stream转成LongStream
mapToDouble:将Stream转成DoubleStream
过滤
filter(pred):根据条件筛选元素。保留 predicate 为 true 的元素1
2.filter(x -> x >= 0)
.filter(f -> f.weight() >= 0.8)takeWhile(pred):从头开始保留,直到第一次不满足就停止(Java 9+)1
.takeWhile(f -> f.weight() >= 0.8)
dropWhile(pred):从头开始丢弃,直到第一次不满足后开始保留(Java 9+)
截取 / 跳过
limit(n):最多取前 n 个(对无限流很重要)1
.limit(50)
skip(n):跳过前 n 个1
.skip(10)
去重 / 排序
distinct():去重(依赖equals/hashCode)1
.distinct()
sorted()/sorted(comparator):排序(sorted稳定排序)1
2.sorted()
.sorted(Comparator.comparingDouble(Fish::weight))注意,如果
观察 / 调试(不改变元素)
peek(action):对每个元素做“旁路操作”,常用于打印调试;仍然惰性1
.peek(System.out::println)
终止:
遍历输出
forEach(action):对每个元素执行操作(并行流顺序不保证)1
.forEach(System.out::println)
forEachOrdered(action):保持顺序(尤其用于并行流)
收集成容器
toList():收集成 List(Java 16+,返回不可修改 list)1
List<Fish> list = stream.toList();
collect(Collectors.toList()):经典写法(通常可修改 list)toArray(...):收集成数组1
Fish[] arr = stream.toArray(Fish[]::new);
聚合 / 归约
reduce(...):把多个元素合并成一个结果(例如求和、求积、拼接等)有初始值(identity)版本:返回一个值
1
int sum = Stream.of(3, 1, -4).reduce(0, (a, b) -> a + b);
无初始值版本:返回 Optional(空流时没有结果)
1
Optional<Integer> sumOpt = Stream.of(3, 1, -4).reduce((a, b) -> a + b);
常见场景:求最大/最小(也可用 max/min)
1
Optional<Integer> maxOpt = Stream.of(3, 1, -4).reduce(Integer::max);
count():计数,返回long(元素个数)AnyMatch():用来判断Stream里是否至少有一个元素满足给定条件(Predicate)。sum():计算总和。只有DoubleStream,IntStream,LongStream有这个(数值专用)方法。
一个典型的Stream处理链条通常是这样的:
Java
1 | List<String> names = Arrays.asList("Anna", "Bob", "Alice", "Mike"); |
输入与输出
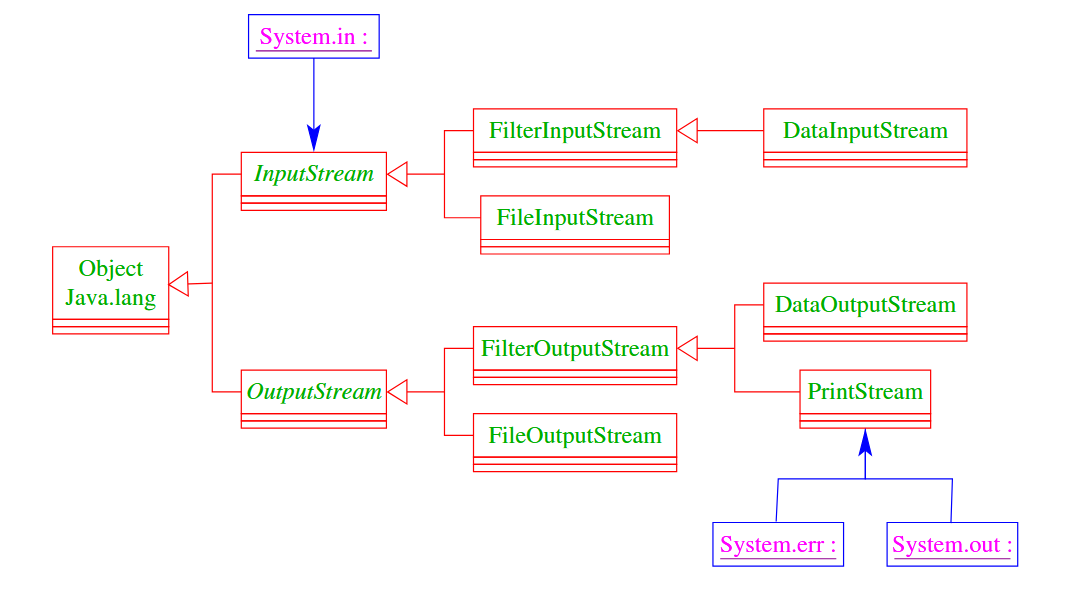
核心概念:流 (Stream)
Java 中的 IO 操作基于流 (Stream) 的概念。流是一个有序的数据序列,有一个源头(Source)和一个目的地(Sink)。
- 输入流 (Input Stream):用于从源头(如文件、键盘、网络)读取数据。
- 输出流 (Output Stream):用于向目的地(如文件、屏幕、网络)写入数据。
面向字节的输入/输出 (Byteweise Ein- und Ausgabe)
这一部分处理的是原始的二进制数据(8位字节),适用于图像、音频或任何非文本数据。
基类 (抽象类):
InputStream: 所有字节输入流的父类。核心方法是read(),每次读取一个字节 。OutputStream: 所有字节输出流的父类。核心方法是write(int b)。
标准输入/输出:
System.in: 标准输入流 (InputStream),通常指键盘输入 。System.out和System.err: 标准输出流 (PrintStream),通常指控制台屏幕 。
常用实现类:
FileInputStream/FileOutputStream: 用于从文件读取或向文件写入字节 。- 装饰器模式 (Decorator Pattern):为了增强功能,Java 允许将流“层层包裹”。
DataInputStream/DataOutputStream: 允许直接读写 Java 基本数据类型(如readInt(),writeDouble()),而不仅仅是字节 。- 例子:
new DataInputStream(new FileInputStream("file.txt"))。
示例代码逻辑:
文件复制:通过循环调用
read()读取字节直到返回 -1,然后用write()写入 。1
2
3
4
5
6
7
8
9
10
11
12import java.io.*;
public class FileCopy {
public static void main(String[] args) throws IOException {
FileInputStream file = new FileInputStream(args[0]);
int t;
// 核心逻辑:循环调用 read() 读取字节,直到返回 -1
while(-1 != (t = file.read()))
System.out.print((char)t); // 这里演示为输出,也可以改为写入文件
System.out.print("\n");
}
}
面向字符的输入/输出 (Textuelle Ein- und Ausgabe)
这一部分处理的是字符数据(16位 Unicode),专门用于处理文本文件,解决了字符编码问题。
基类 (抽象类):
Reader: 所有字符输入流的父类 。Writer: 所有字符输出流的父类 。
桥接流 (转换流):
InputStreamReader和OutputStreamWriter: 它们是字节流和字符流之间的桥梁,负责将字节流解码为字符流,或将字符流编码为字节流 。
常用实现类:
FileReader/FileWriter: 方便地读取和写入文本文件 。BufferedReader: 非常重要。它提供了缓冲功能,提高了读取效率,并且提供了readLine()方法,可以一次读取一行文本 。PrintWriter: 提供了方便的打印方法(如println()),常用于输出文本 。
示例代码逻辑:
统计行数:使用
BufferedReader包装FileReader,循环调用readLine()直到返回null。1
2
3
4
5
6
7
8
9
10
11
12
13
14import java.io.*;
public class CountLines {
public static void main(String[] args) throws IOException {
FileReader file = new FileReader(args[0]);
BufferedReader buff = new BufferedReader(file);
int n = 0;
// 核心逻辑:循环调用 readLine() 直到返回 null
while(null != buff.readLine())
n++;
buff.close();
System.out.print("Number of Lines:\t\t"+ n);
}
}
文件处理
例子:
假设我们现在有一个对象Pengui,带3个属性:
1 | package pgdp.io; |
然后我们现在希望利用文件存储/读取这种对象。
写入:
1 | public void save(Penguin p, String filename) { |
try():括号里的东西算with,就是这里定义的东西可以在try的实际部分调用FileWriter(filename):负责真正地将内容写入进文件new BufferedWriter(...):加一层缓冲,并且提供newLine()等便捷方法newLine():换行String.valueOf():数转字符串IOException:“输入/输出异常”(Input/Output Exception)
读取:
1 | public Penguin load(String filename) { |
Integer.parseInt():字符串转intDouble.parseDouble():字符串转double
并行运行与同步
创建线程
一般有2种方法:
继承
Thread:重写run(),对线程对象调用start()后,系统会初始化新线程并并行执行该对象的run();当前执行流会继续往下走。例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class MyThread extends Thread {
public void hello(String s) {
System.out.println(s);
}
public void run() {
hello("I’m running ...");
} // end o f run ( )
public static void main(String[] args) {
MyThread t = new MyThread();
t.start();
System.out.println("Thread has been started ...");
} // end o f main ( )
} // end of class MyThread
实现
Runnable:实现run(),用new Thread(runnableObj)包一层,再start()。优点是还能继承别的类。例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class MyRunnable implements Runnable {
public void hello(String s) {
System.out.println(s);
}
public void run() {
hello("I’m running ...");
} // end o f run ( )
public static void main(String[] args) {
Thread t = new Thread(new MyRunnable());
t.start();
System.out.println("Thread has been started ...");
} // end o f main ( )
} // end of class MyRunnable
调度
但是这样单纯地创建线程并不能保证它们的实际运行顺序。
start():进入 ready,等待被调度执行yield():让出 CPU(回到 ready 的直觉)sleep():进入 sleeping,到时间再回 ready1
public static void sleep (int msec) throws InterruptedException
join():进入 joining,等待另一个线程结束
每个线程对象都有一个joiningThreads队列:如果t1调用t2.join(),t1会暂停并等待t2结束;t2结束后会唤醒所有等待它的线程。
例子:
1 | private static int count = 0; |
先定义了一个全局的(共享的)数组task,用它来记录每个线程,以便每个线程都可以通过这个数组找到其他线程。所以最后会输出:
1 | Thread-1 joined Thread-0 |
线程3会通过join等待线程2,线程2会等待线程1。
Monitor
synchroized
用synchroized来控制需要保护的资源,给它创建kritische Abschnitt。
synchronized只能用在:
- 方法:
public synchronized void openShop() { ... } - 代码块:
synchronized(this) { ... }
例子:
1 | public class Count { |
会输出:
1 | Thread-0 read 0 |
ReadWrit-lock
1 | public class RW{ |
这里synchronized的作用:
- 互斥访问:同一时间只能一个线程修改
countReaders(防止竞态) - 提供 wait/notify 的前提:
wait()和notifyAll()必须在持有同一对象锁时调用(这里锁的是this)
也就是说:这里把 RW 对象本身当作内部管理锁。
当在实例方法前面写 synchronized 时,它锁的是调用该方法的那个对象(this)的监视器锁。
1 | class A { |
等价于:
1 | class A { |
如果想要分开保护一个对象的不同attribute,可以:
1 | public class A { |
volatile
而想要监控某个字段的话就需要用volatile,它主要的作用是:
可见性:
写
volatile:必须把新值刷新到主内存。读
volatile:必须从主内存读取最新值。所以等待线程就能看见主线程的更新。
有序性:
会先修改
volatile字段,然后其他线程才可以读它。
但是volatile不能确保原子性。
例子:
1 | package pgdp.memoryvisibility; |
Semaphor
可以直接用JAVA里的Semaphor。
例子:
1 | import java.util.concurrent.Semaphore; |
.acquire():请求进入.release():退出
Consumer-Producer问题:
设置3个Semaphore:
free:控制满了不能放occupied:控制空了不能取mutex:控制同时只能一个进程改数组和指针
1 | import java.util.concurrent.Semaphore; |
例子
计算数列和
1 | package pgdp.threads; |
1 | package pgdp.threads; |
或者用实现Runnable的写法:
1 | package pgdp.threads; |
1 | package pgdp.threads; |