
什么是SQL?
SQL(Structured Query Language,结构化查询语言)是一种用于定义、查询和管理关系型数据库的一种声明式语言。
声明式语言指的是:只需要描述想要什么结果(例如要哪些数据、满足什么条件),而不必编写具体怎么一步步实现的过程。具体的执行方式由数据库的查询优化器与执行引擎决定。
它主要用来做这些事:
- 查询数据(DQL):比如
SELECT,从表里查数据、过滤、排序、分组等 - 定义数据库结构(DDL):比如
CREATE / ALTER / DROP,创建/修改/删除表、索引、视图等 - 操作数据(DML):比如
INSERT / UPDATE / DELETE,新增、修改、删除表中的记录 - 权限控制(DCL):比如
GRANT / REVOKE,给用户授权或收回权限 - 事务控制(TCL):比如
COMMIT / ROLLBACK / SAVEPOINT,控制事务提交、回滚等
基础
一般的SQL查询语句的语法顺序/结构如下:
1 | SELECT [DISTINCT] <select_list> |
SELECT:选择列DISTINCT:去重FROM:选择表格WHERE:筛选条件GROUP BY:分组HAVING:对分组后的结果过滤ORDER BY:排序ASC:升序DESC:降序
LIMIT:截断返回行数
而它们的执行顺序是:FROM → WHERE → GROUP BY → HAVING → SELECT → DISTINCT → ORDER BY → LIMIT
入门
以这个数据库为例( https://hyper-db.de/interface.html )
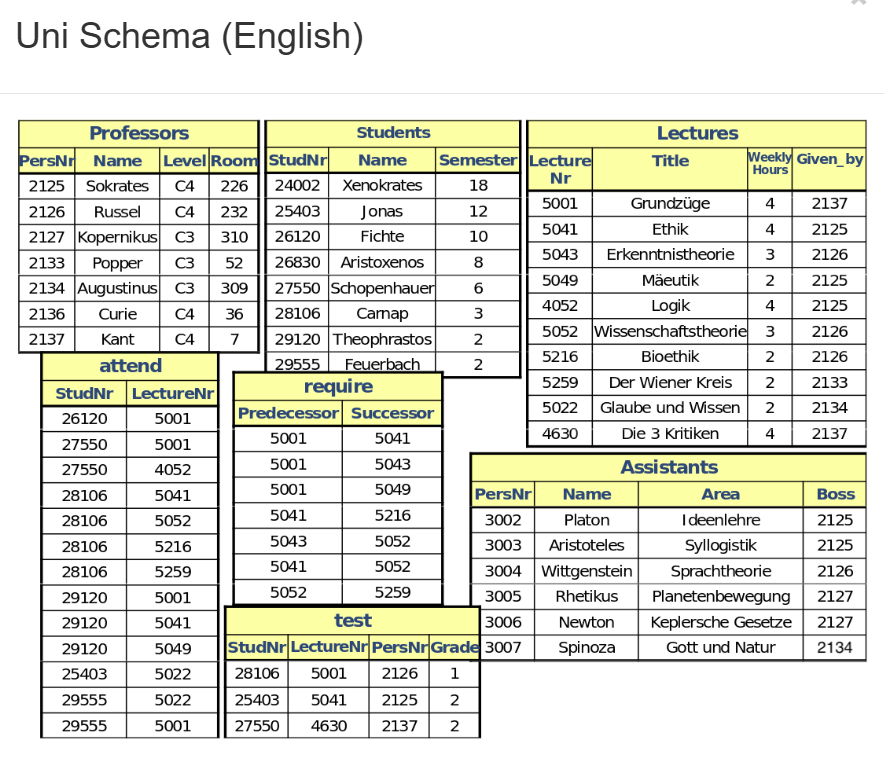
如果我们想知道一共有哪些教授,那么我们只需要:
- 列出Professors这张表里的
- Name这一列的所有内容
对应的命令:
SELECT后跟列名FROM后跟表名
1 | SELECT Name |
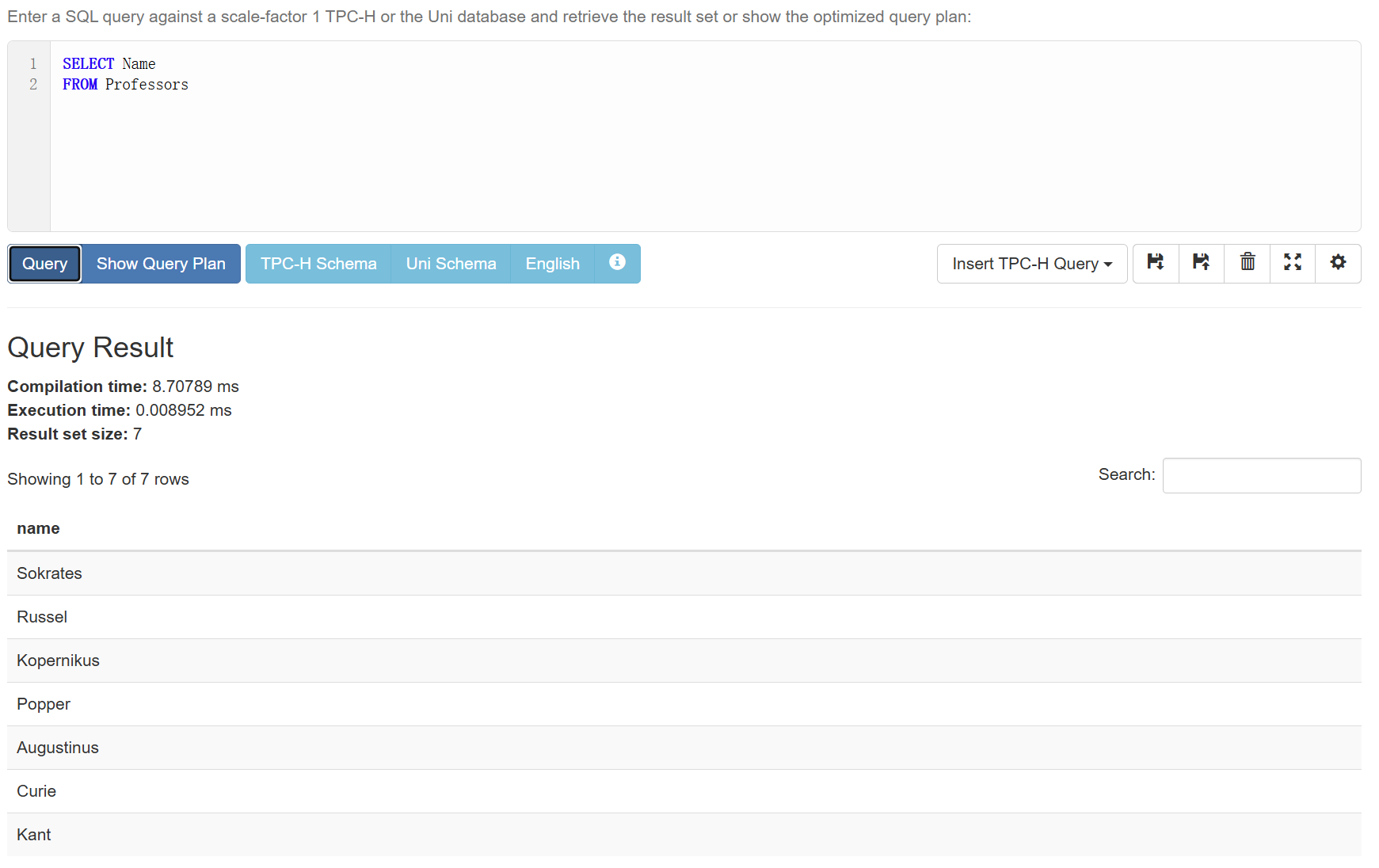
DISTINCT
假如我们只关注Professors表里一共有多少种不同的Level:
如果用之前的方法它会重复输出:
1 | SELECT Level |
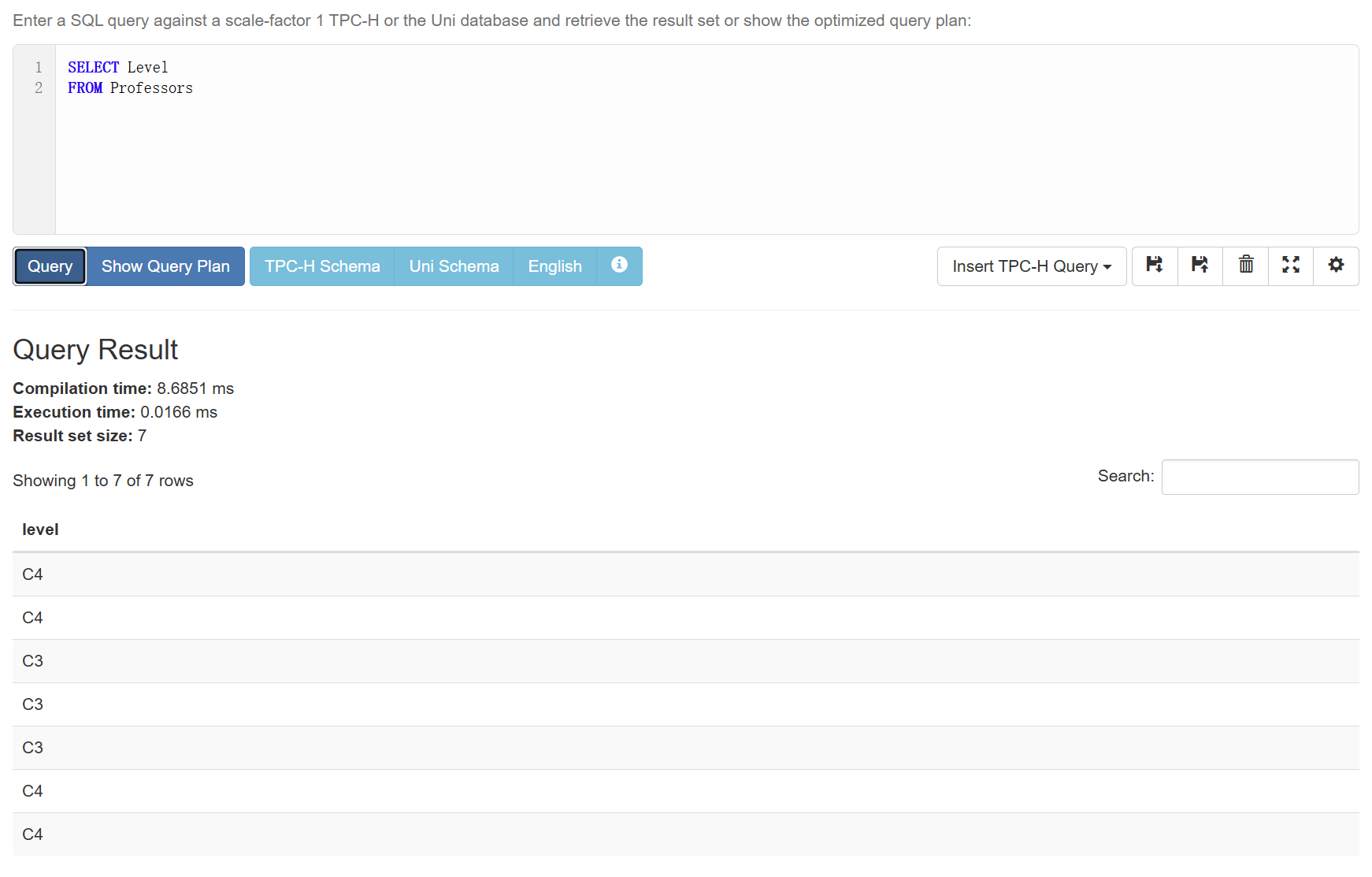
所以我们需要用DISTINCT来去重:
1 | SELECT DISTINCT Level |
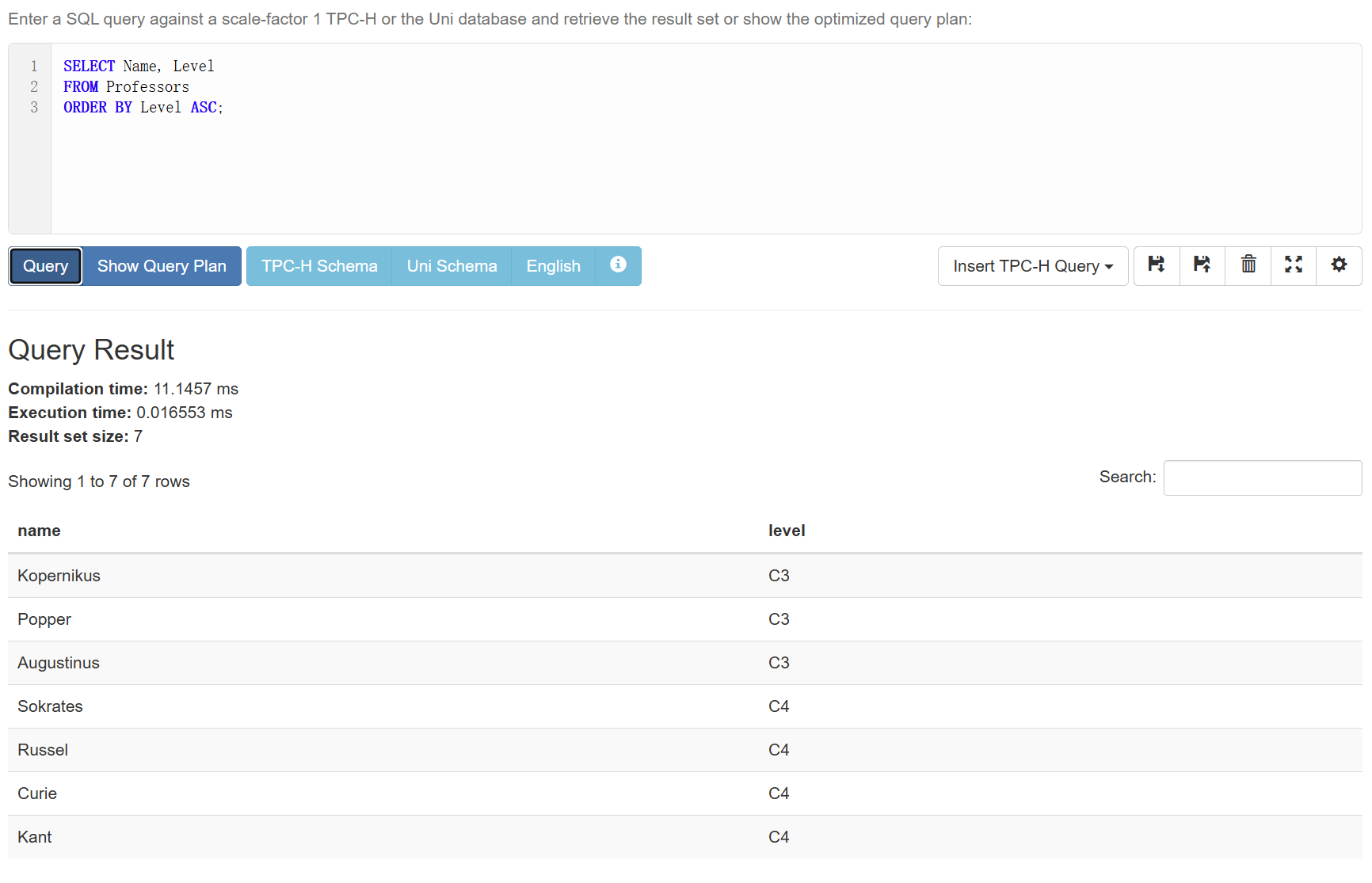
ORDER BY
在结果较多时我们往往希望将结果排序以便我们后续操作,这是需要用到ORDER BY:
ASC:升序DESC:降序
默认是升序(ASC)。
1 | SELECT Name, Level |
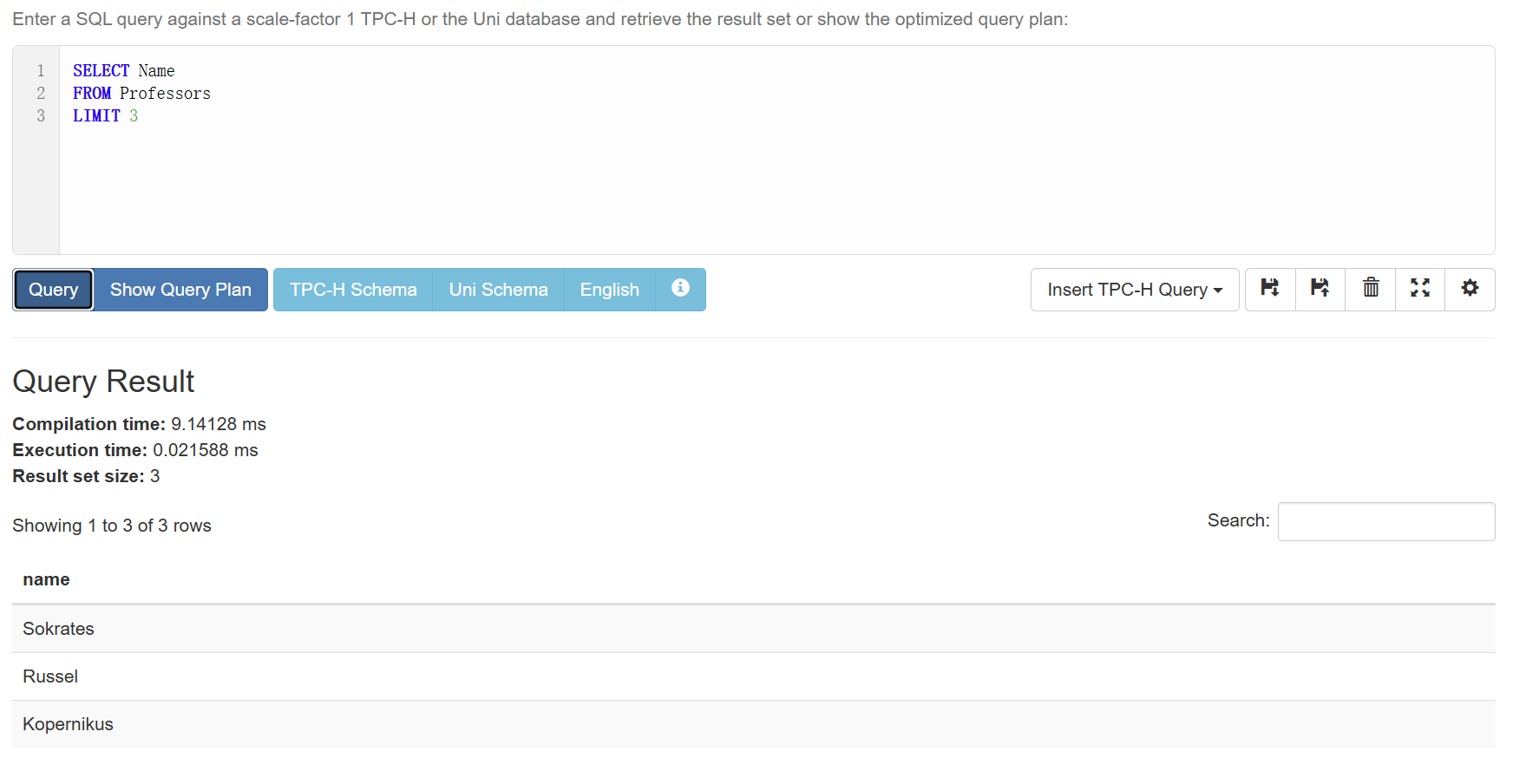
LIMIT
也可以只查看前几条结果:
1 | SELECT Name |
OFFSET
和LIMIT类似,只不过是查看从第几条开始之后的结果。
配合LIMIT一起用可以直接锁定某个排名的人:
1 | SELECT Name, Semester |
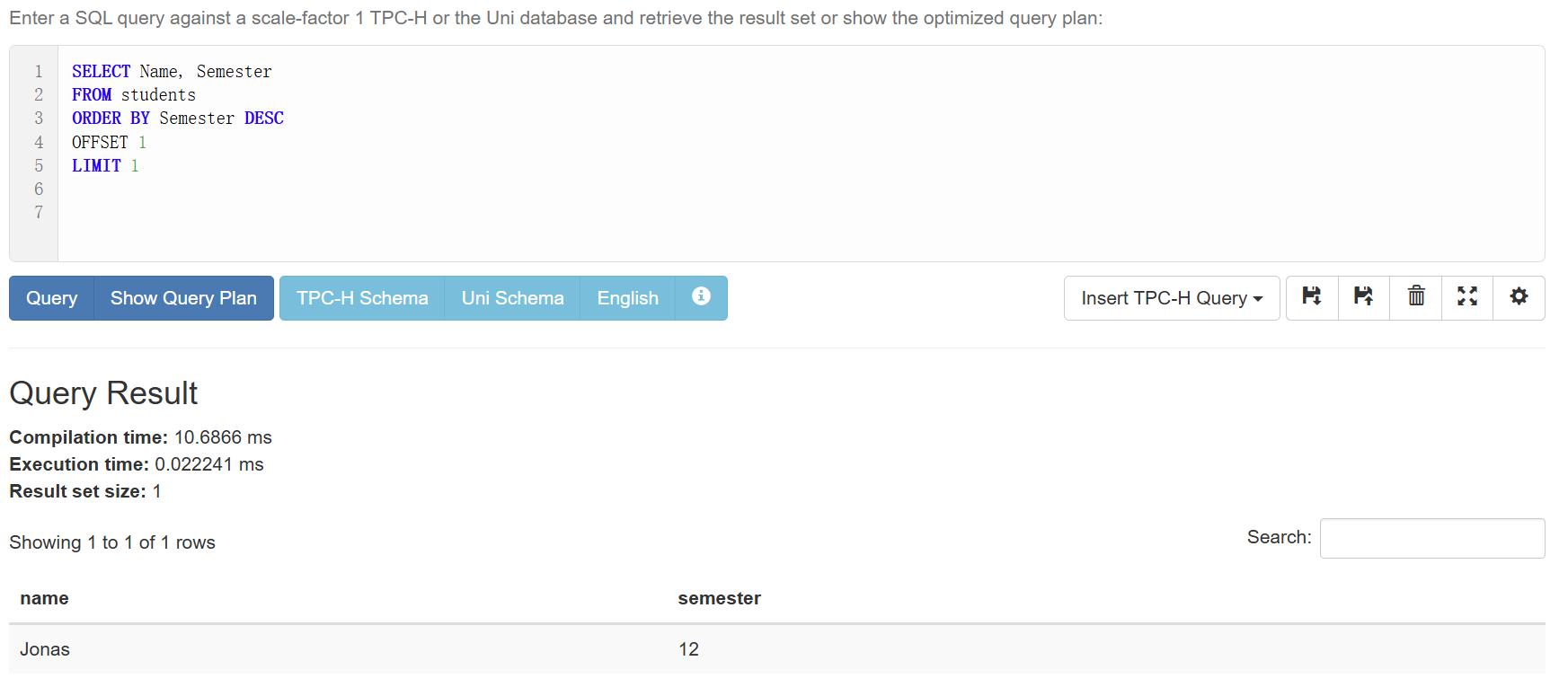
注意,offset是从0开始的。
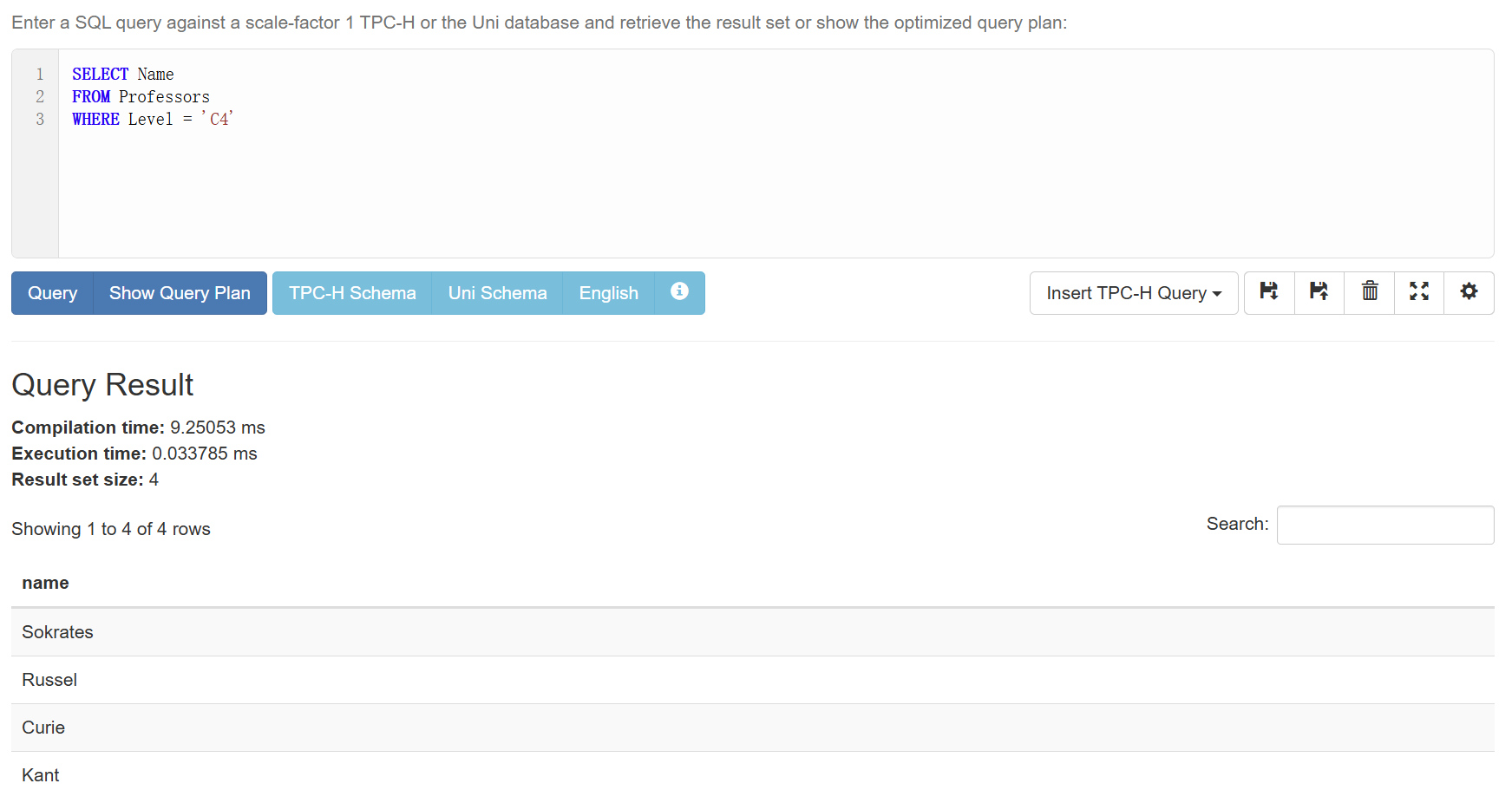
WHERE
如果现在想要加上一点条件,比如说只显示Level等于C4的教授,那么就是:
WHERE后面跟筛选条件
1 | SELECT Name |
命名
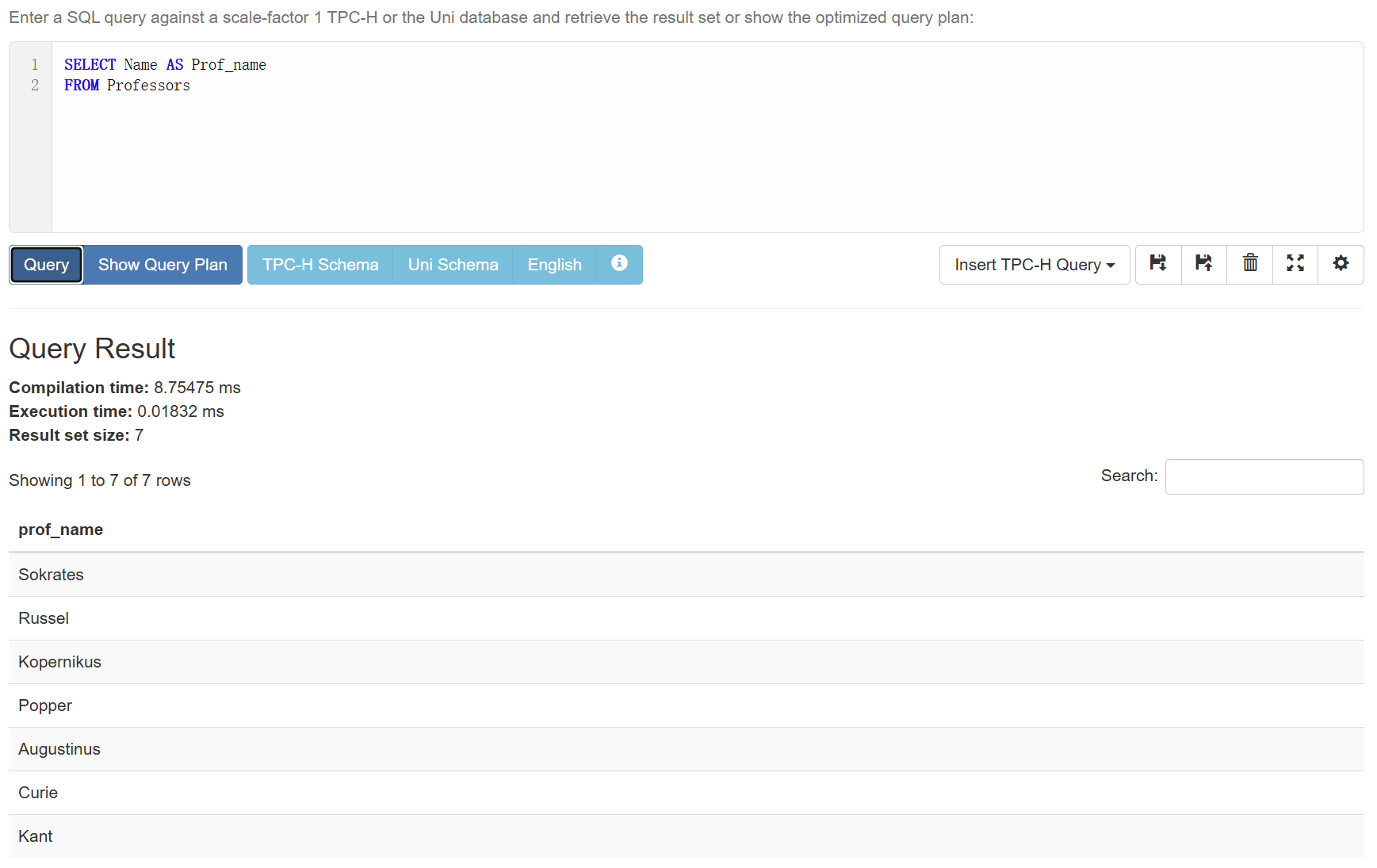
有时我们希望自己命名查询结果的列名,这时候就需要AS:
1 | SELECT Name AS Prof_name |
除此之外,有些时候筛选会遇到2个表里有相同的列名,这个时候就需要命名每个表以此来区分:
- 在每个表后加上空格以及新的名字(例如
Students s) - 在之后的部分就可以用s指代这张表
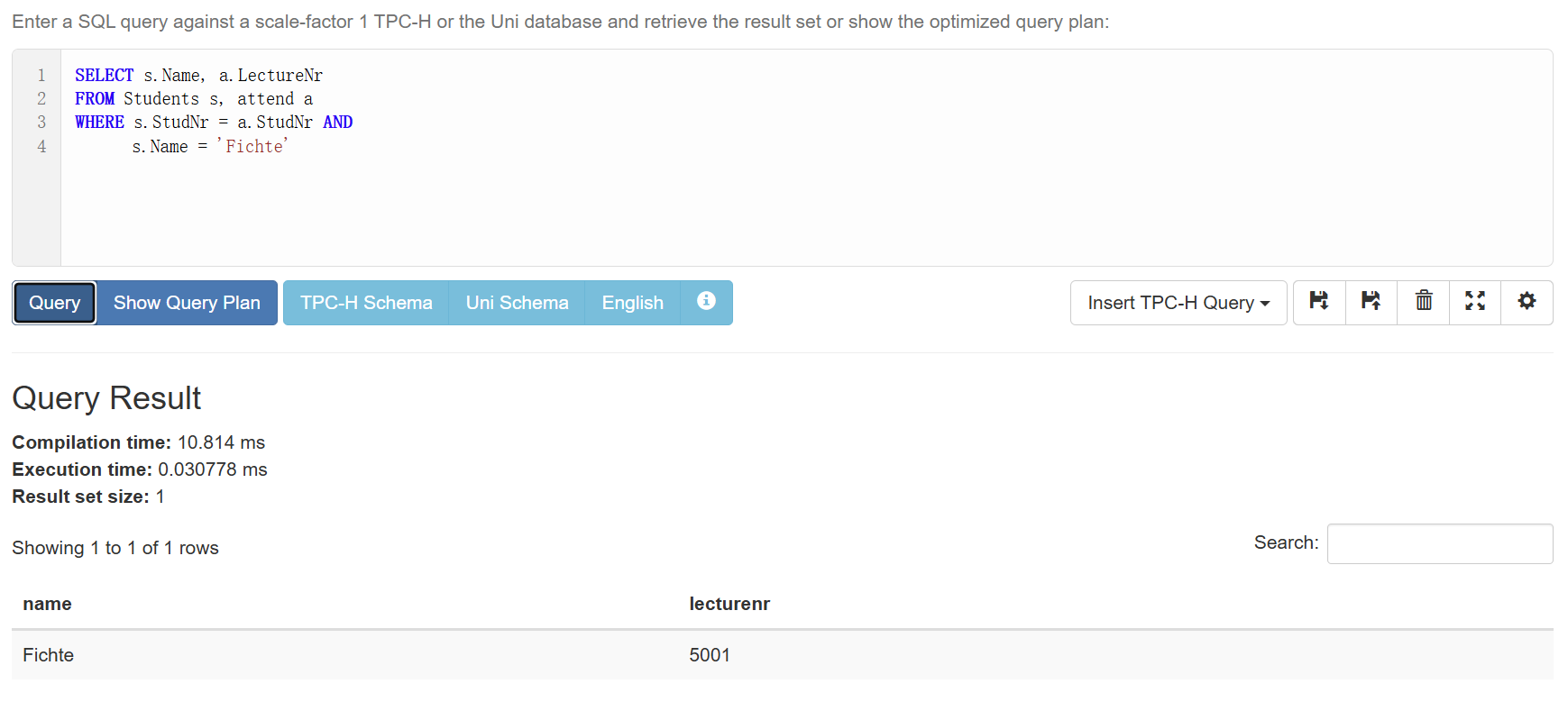
比如说我们想知道学生”Fichte”上了哪些课:
1 | SELECT s.Name, a.LectureNr |
COUNT
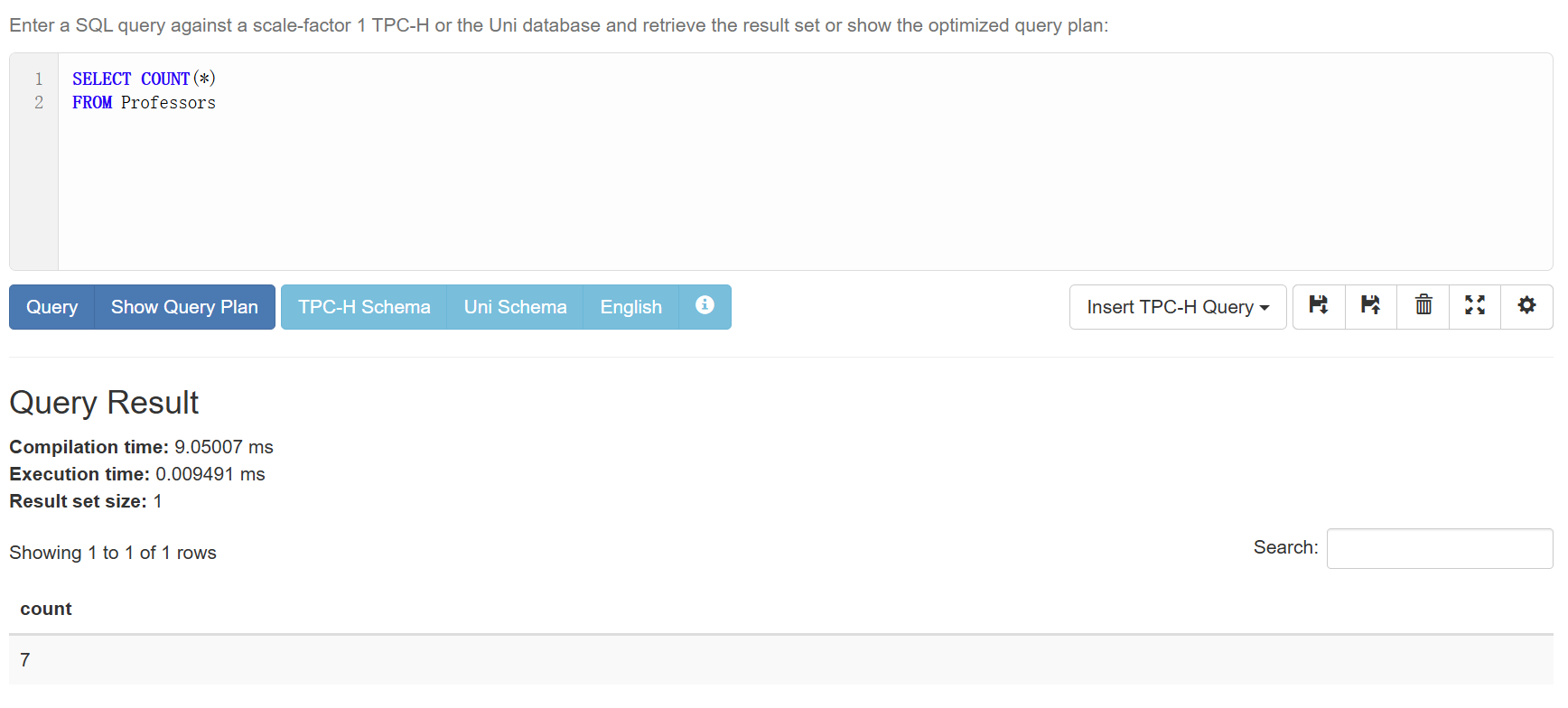
如果我们想知道一共有多少名教授,就需要COUNT来帮助我们数数:1
2SELECT COUNT(*)
FROM Professors
GROUP BY
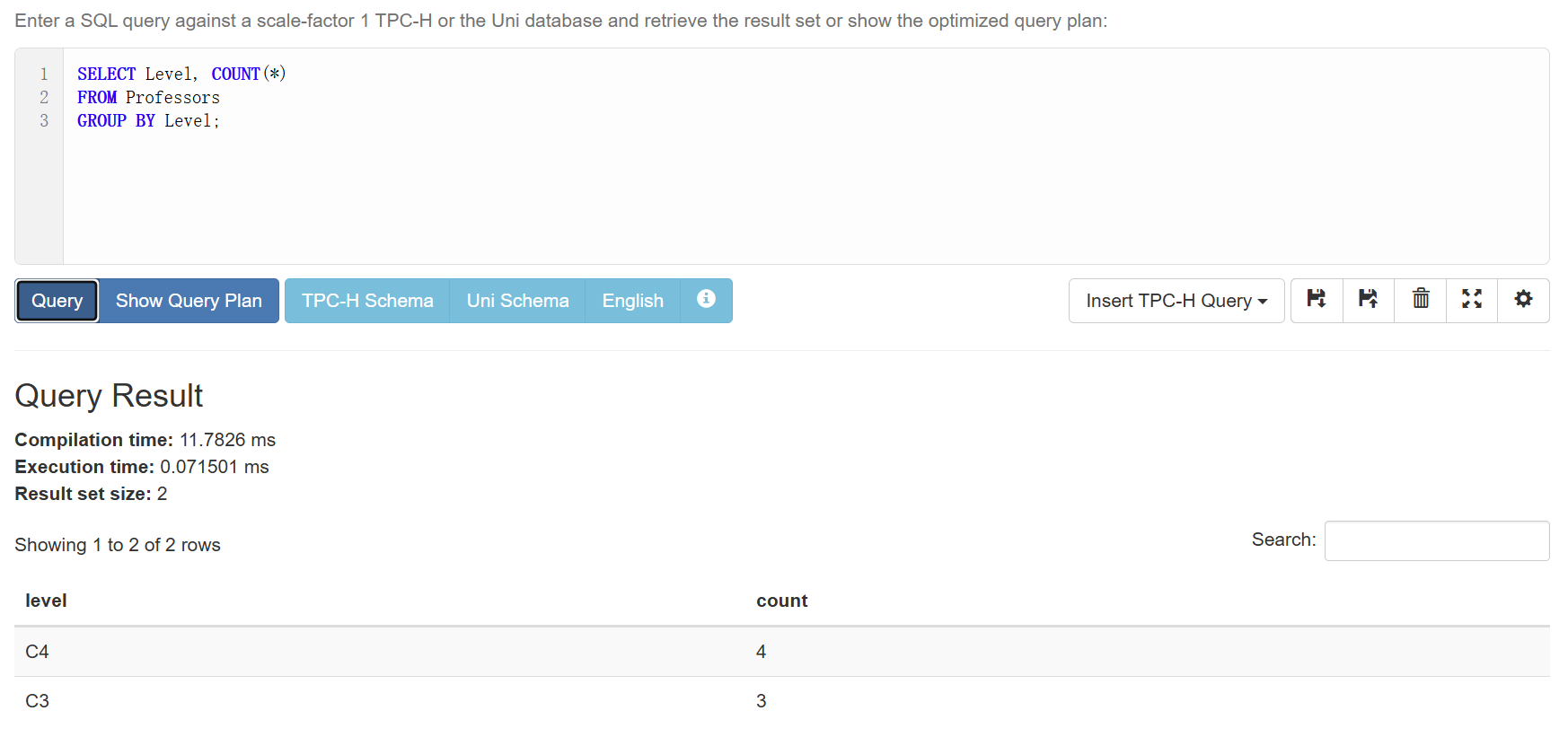
如果我们想知道每个Level各有多少教授,就需要GROUP BY来帮助我们进行分组:
1 | SELECT Level, COUNT(*) |
在 GROUP BY 查询里,SELECT 里出现的每个表达式必须满足二选一:
- 是分组键(出现在
GROUP BY里,或能由分组键唯一决定),或者 - 是聚合表达式(被
SUM/AVG/COUNT/MIN/MAX/...包起来)
否则:
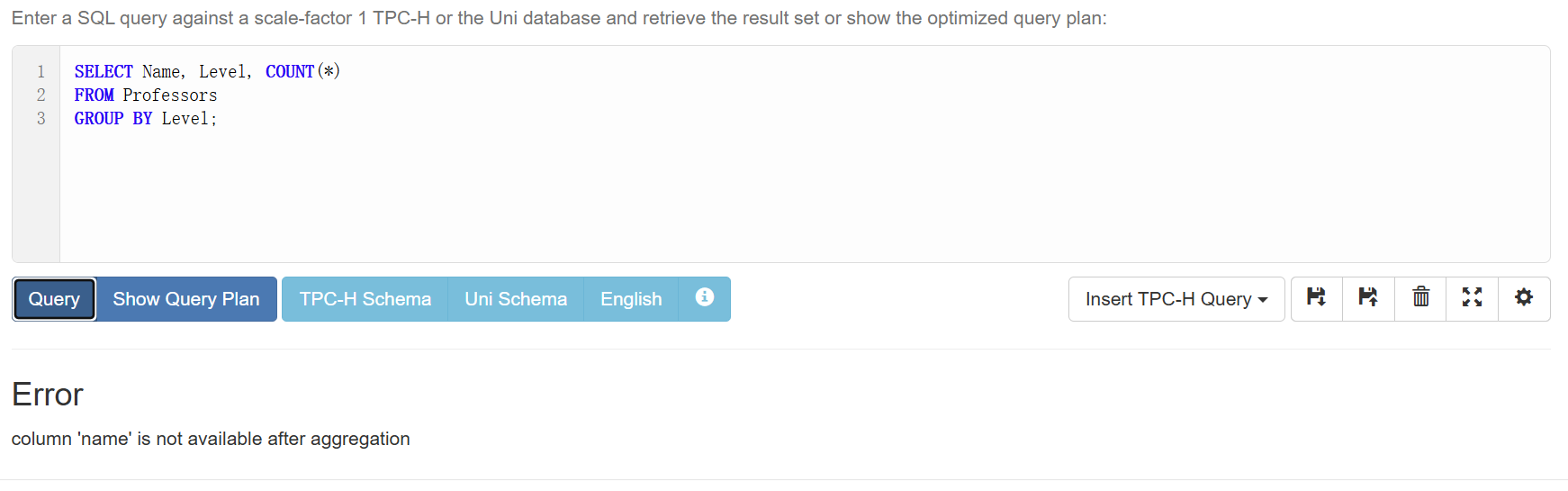
但是通过GROUP BY a, b, c这种只会得到最细粒度的分组,即每个(a,b,c)一行。
那我们同时还想得到更粗颗粒度的分组结果(比如按照(a,b),(a),(a,c)这些分组)该怎么办呢?
最普通的方法就是用UNION ALL:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19SELECT
a, NULL AS b, c,
COUNT(*) AS cnt
FROM t
GROUP BY a, c
UNION ALL
SELECT
NULL AS a, b, c,
COUNT(*) AS cnt
FROM t
GROUP BY b, c
UNION ALL
SELECT
a, NULL AS b, NULL AS c,
COUNT(*) AS cnt
FROM t
GROUP BY a
当然,还有很多更加便捷的方法:
GROUPING SETS
可以用GROUPING SETS来定义多个想要的分组:
1 | GROUP BY GROUPING SETS ( |
其中 () 是全表总计(grand total),只按“空分组”汇总一次。
CUBE
1 | GROUP BY CUBE(a,b,c) |
CUBE会处理所有子集分组。即当维度(CUBE括号里的列个数)为n时,会产生$2^n$种分组。
例如n=3时,一共8种:
- (a,b,c)
- (a,b)
- (a,c)
- (b,c)
- (a)
- (b)
- (c)
- () 全表总计
CUBE的输出里某些维度列会出现NULL,它代表这一行在该维度上“被汇总掉了”(对所有该维度值求和/求平均等)。比如说在按照(a,b)分组的部分内容里,那么c栏内容就会是NULL。
因为CUBE会显示/返回所有分组层级的结果,所以通常要用WHERE ... IS NULL来挑某一层。
例子:只要按(a,b)的汇总,即c IS NULL:
1 | SELECT a, b, s |
ROLLUP
与CUBE不同,ROLLUP会沿着维度列表“逐层向上汇总。
1 | GROUP BY ROLLUP(a,b,c) |
例如n=3的情况,ROLLUP会计算这几个分组:
(a,b,c)
(a,b)
(a)
()
不会处理(a,c)之类的分组结果。
HAVING
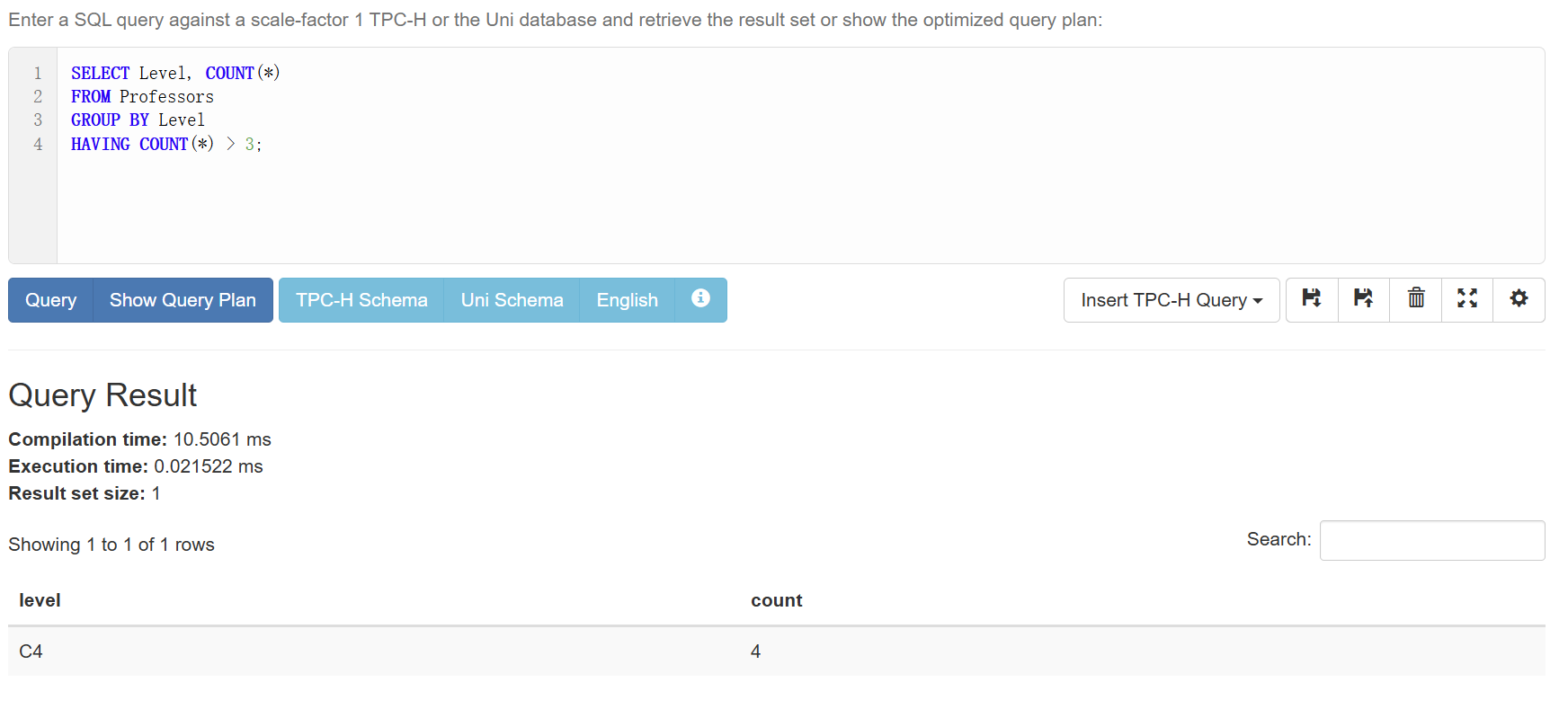
在分组的基础上我们往往希望再加点筛选条件,这个时候就需要HAVING来对分组后的结果过滤。
比如说我们想知道哪些Level的人数超过了3:
1 | SELECT Level, COUNT(*) |
子查询/嵌套
假如我们想知道哪些学生的学期数在平均学期数以下,就需要拆成2步来完成
计算平均学期数(先生成一个子列表)
1
2SELECT AVG(Semester)
FROM Students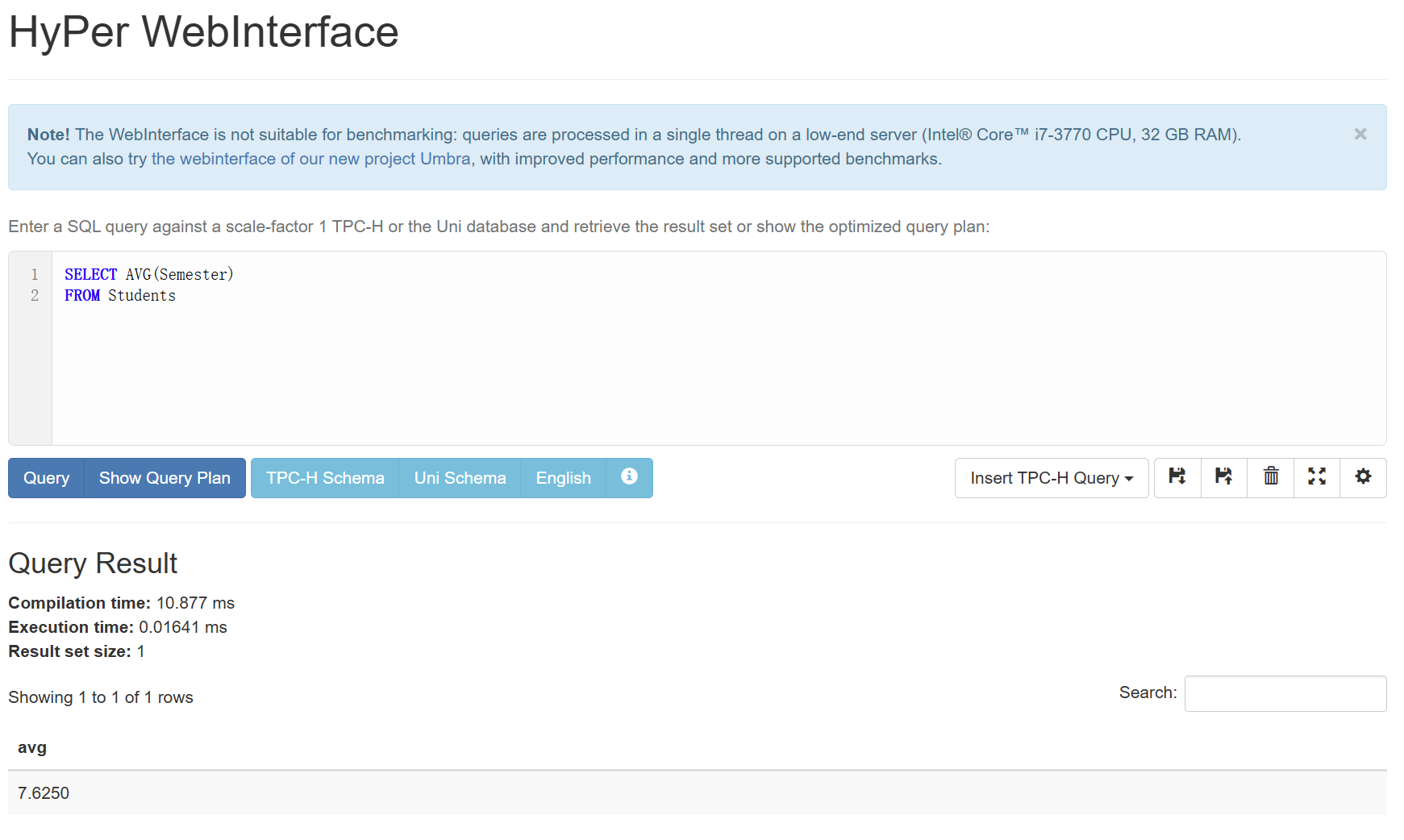
筛选
1
2
3SELECT Name
FROM Students
WHERE Semester <
拼起来就是:
1 | SELECT Name |
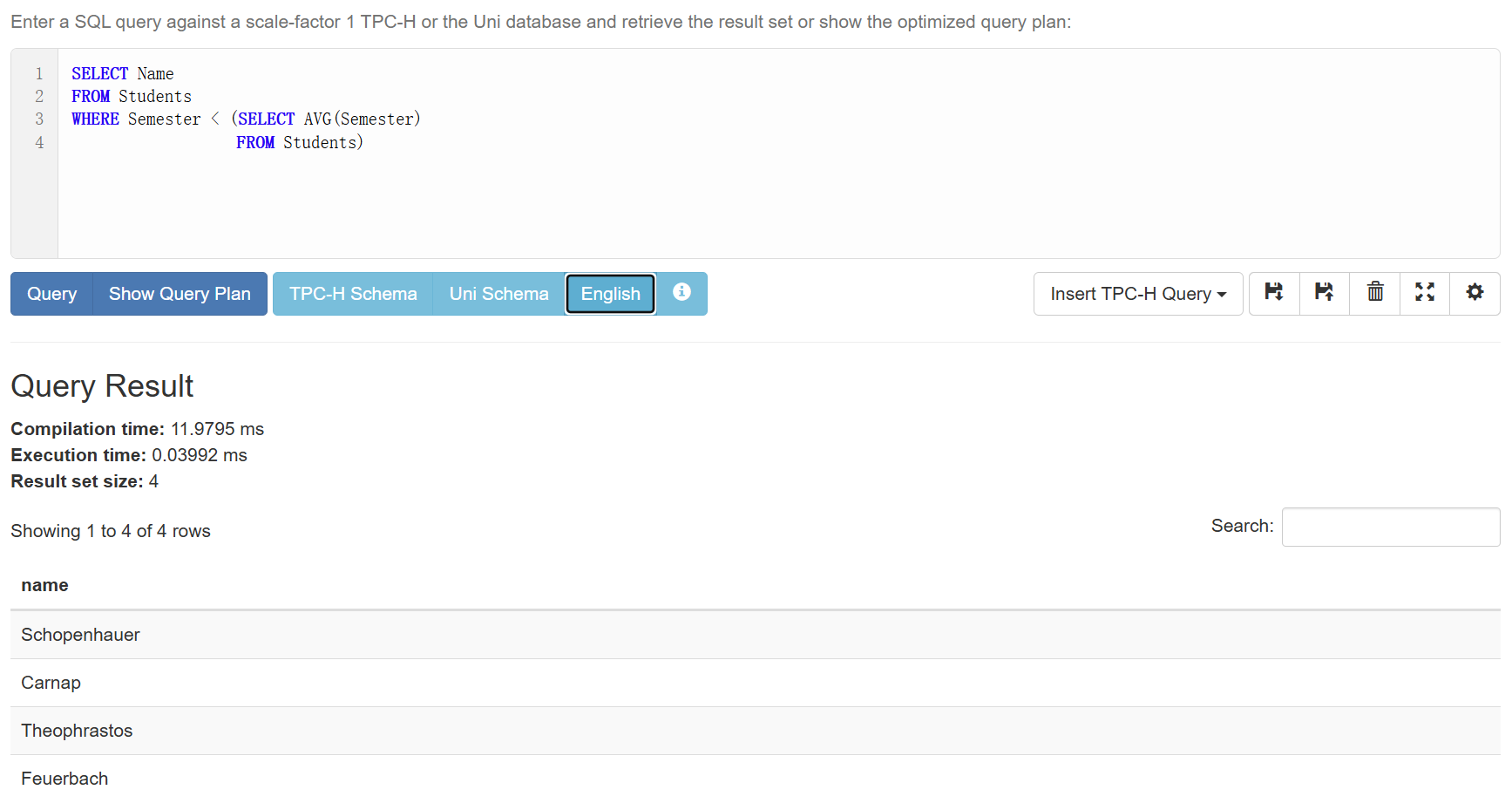
或者也可以:
1 | SELECT Name |
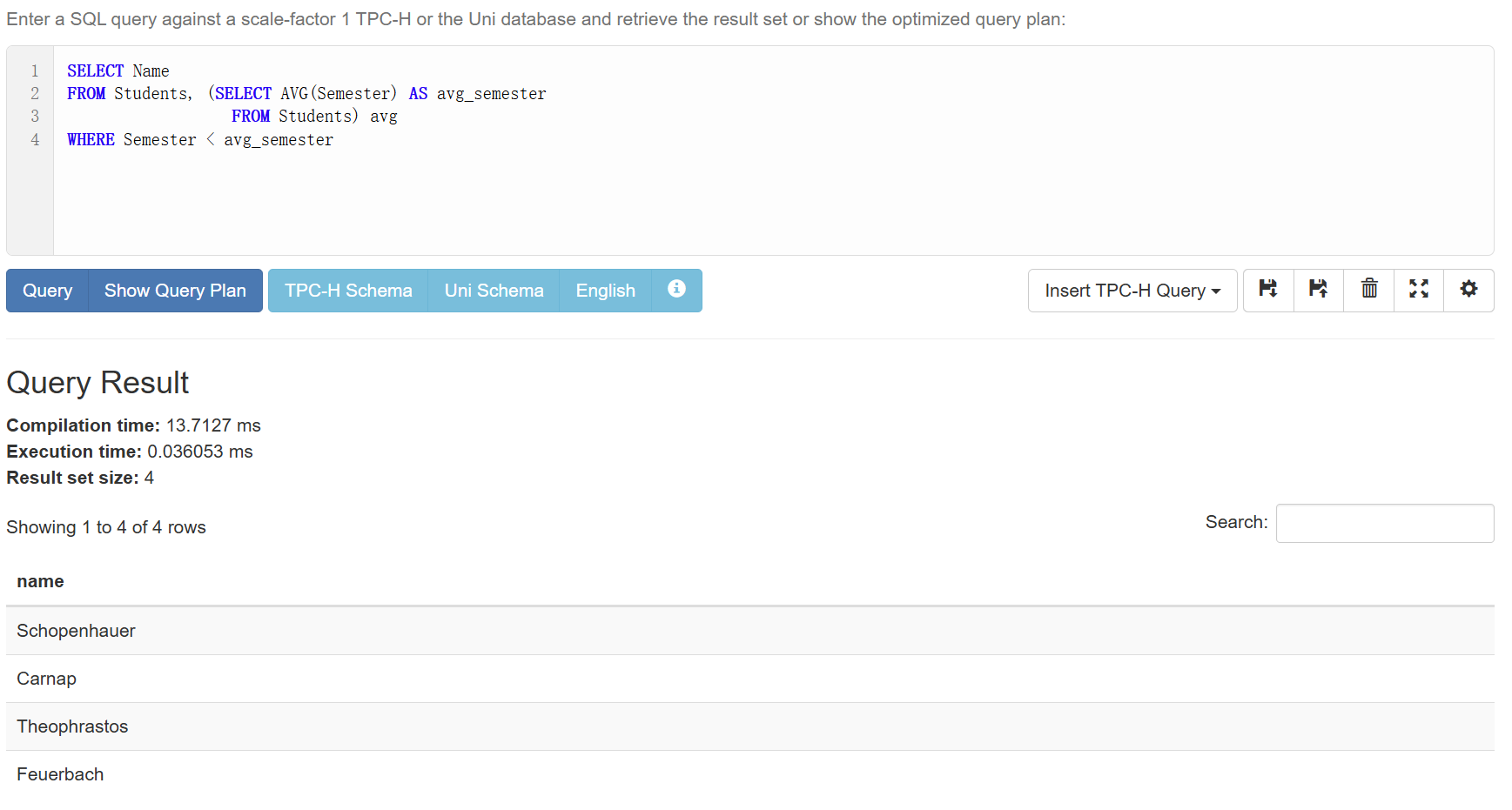
这样会高效很多。
LATERAL
LATERAL允许FROM子句中的派生表/子查询/表函数引用其左侧 FROM 项的列,从而形成相关(correlated)的行源,并对左侧输入的每一行进行求值。
例子:
1 | SELECT * FROM |
这段等价于:
1 | for x in [1]: |
集合比较与存在性
IN
判断是否属于集合。
比如说我们想知道哪些学生参加了5001这门课,并且最后输出它们的名字,那么我们就可以用IN来进行判断:
1 | SELECT s.Name |
ANY
对集合里至少一个成立。
比如说我们想找出房间号比某个 C3 教授房间更大的教授:
1 | SELECT p.Name, p.Room |
ALL
比如说我们想找出房间号比所有 C3 教授房间都小的教授和房间:
1 | SELECT p.Name, p.Room |
EXISTS
比如说我们想找出至少开了一门课的教授:
1 | SELECT p.Name |
NOT EXISTS
找出没有学生选的课程:
1 | SELECT l.LectureNr, l.Title |
Common Table Expression (CTE) / WITH AS
CTE的核心动机:
可读性/结构化
多层嵌套查询堆起来很难读
CTE 可以“给每一步命名”,让外层查询更清爽
可复用
- CTE 的结果可以在同一个查询里被引用多次(比重复写子查询好)
CTE具体用到的命令就是WITH AS。
WITH AS的功能是在一条 SQL 里给一段子查询/临时结果起名字,后面就能像用表一样用它。
注意,WITH AS和子查询是等价的,但是用WITH AS会更容易阅读和理解。
基本语法:
1 | WITH 名字(可选列名列表) AS ( |
一条SQL也可以写多个 CTE,用逗号隔开:
1 | WITH cte1 AS (...), |
例子:查询C4教授的房间(先找C4教授,再查询他们的房间)
1 | WITH C4Prof AS ( |
也可以用VALUES临时造数据:
1 | WITH Professors ( persnr , name , paygrade , room , salary , taxclass ) as |
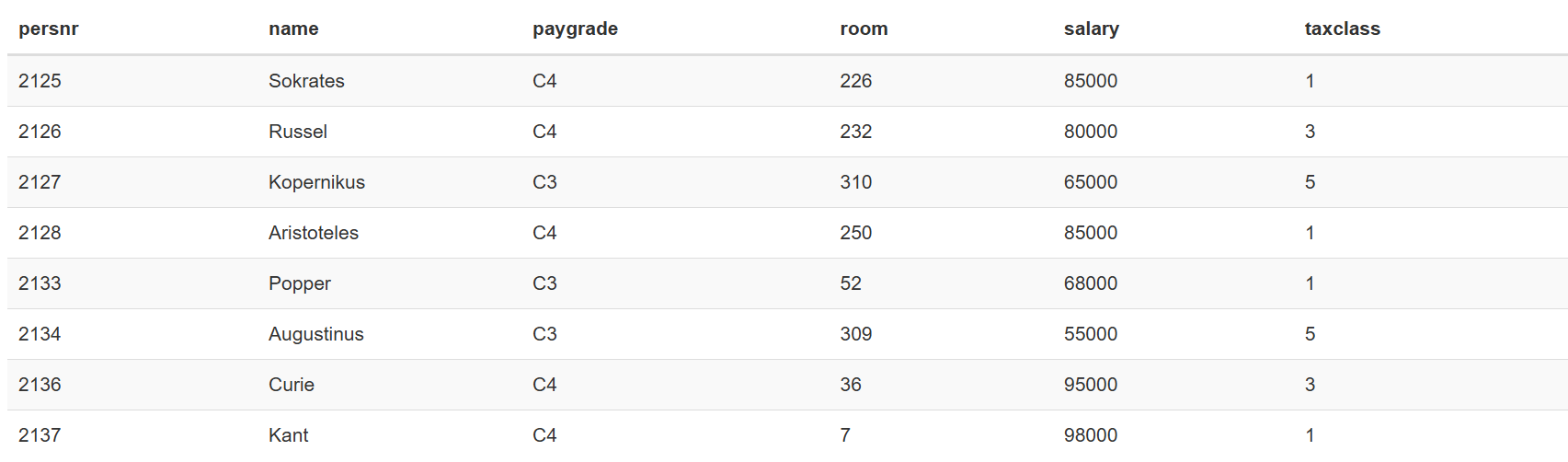
又或者是之前这个例子:
1 | SELECT Name |
改成用WITH AS就是:
1 | WITH avg AS (SELECT AVG(Semester) AS avg_semester |
同时命名多个临时结果时只需要写一个WITH:
1 | WITH examination ( MatrNr , CourseNr , PersNr , Grade ) as ( |
COALESCE
COALESCE 是 SQL 里的空值处理函数:
按从左到右的顺序,返回第一个不是 NULL 的值;如果全是 NULL,就返回 NULL。
1 | COALESCE(a, b, c, 0) |
等价于:如果 a 不是 NULL 返回 a,否则看 b,否则看 c,否则返回 0。
并且
1 | SELECT COALESCE(description, 'None') |
等价于
1 | SELECT CASE WHEN description is NOT NULL |
处理字符串
字符串匹配:
Like:%任意长度(可空),_单字符
常见字符串函数(SQL-92/常见实现):
SUBSTRING(str, start, len)UPPER(str)(也常见LOWER)
字符串拼接:
- 标准:
|| - 也提到某些系统有
+或CONCAT(a,b)(方言差异)
建表
基础
1 | CREATE TABLE Students ( |
含义:
CREATE TABLE 表名 (...):创建表- 括号里每行:
列名 数据类型
常见数据类型(不同库略有差别):
- 整数:
INT/BIGINT - 小数:
DECIMAL(p,s)(精确)/DOUBLE(浮点) - 字符串:
VARCHAR(n)/TEXT - 日期时间:
DATE/TIMESTAMP - 布尔:
BOOLEAN
约束
但我们往往需要加上些条件,比如说非空,指定主键:
主键
PRIMARY KEY(唯一 + 非空)NOT NULL(不允许空)UNIQUE(不允许重复)DEFAULT(缺省值)CHECK(自定义规则)1
Grade DECIMAL(2,1) CHECK (Grade >= 1.0 AND Grade <= 5.0)
例子:
1 | CREATE TABLE Professors ( |
CTAS
CREATE TABLE AS SELECT(简称 CTAS),就是用查询结果建表。
例子:
1 | CREATE TABLE C4_Professors AS |
特点:
- 新表会包含查询出来的列
- 很多数据库会把类型推导出来
- 约束(主键/外键/NOT NULL 等)通常不会自动带过去(不同库细节不同),需要另加
临时表(TEMP / TEMPORARY)
只在当前会话存在,断开就没了:
1 | CREATE TEMP TABLE tmp_top_students AS |
窗口函数(Window functions)
窗口函数(window function)可以把它理解成:“对每一行,都能基于‘一组相关的行’计算出一个值,但又不会把行合并掉”。
窗口函数一般写在 SELECT部分(也可用于 ORDER BY)。并且由于窗口函数的计算发生在 WHERE/GROUP BY/HAVING 之后,因此通常不能直接出现在这些子句(以及 JOIN ON)里。
和之前的分组(GROUP BY)的区别:
- 普通聚合 + GROUP BY:会把多行“压成一行”(一组只剩一行)。
- 窗口函数:每一行都还在,但可以在每一行旁边附加一个聚合/排名/累计值。
窗口函数的典型形式是:
1 | <窗口函数>(...) OVER ( |
PARTITION BY ...:按什么分组(每组独立算)ORDER BY ...:组内顺序(排名/累计/相邻必备)Frame:ROWS .../RANGE ...ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING(按行数滑窗)RANGE BETWEEN 5000 PRECEDING AND 5000 FOLLOWING(按值范围滑窗)
例子1:比如说我们同时想知道每个学生上的课的总数以及具体是哪些课的话,就需要:
1 | SELECT s.name, |
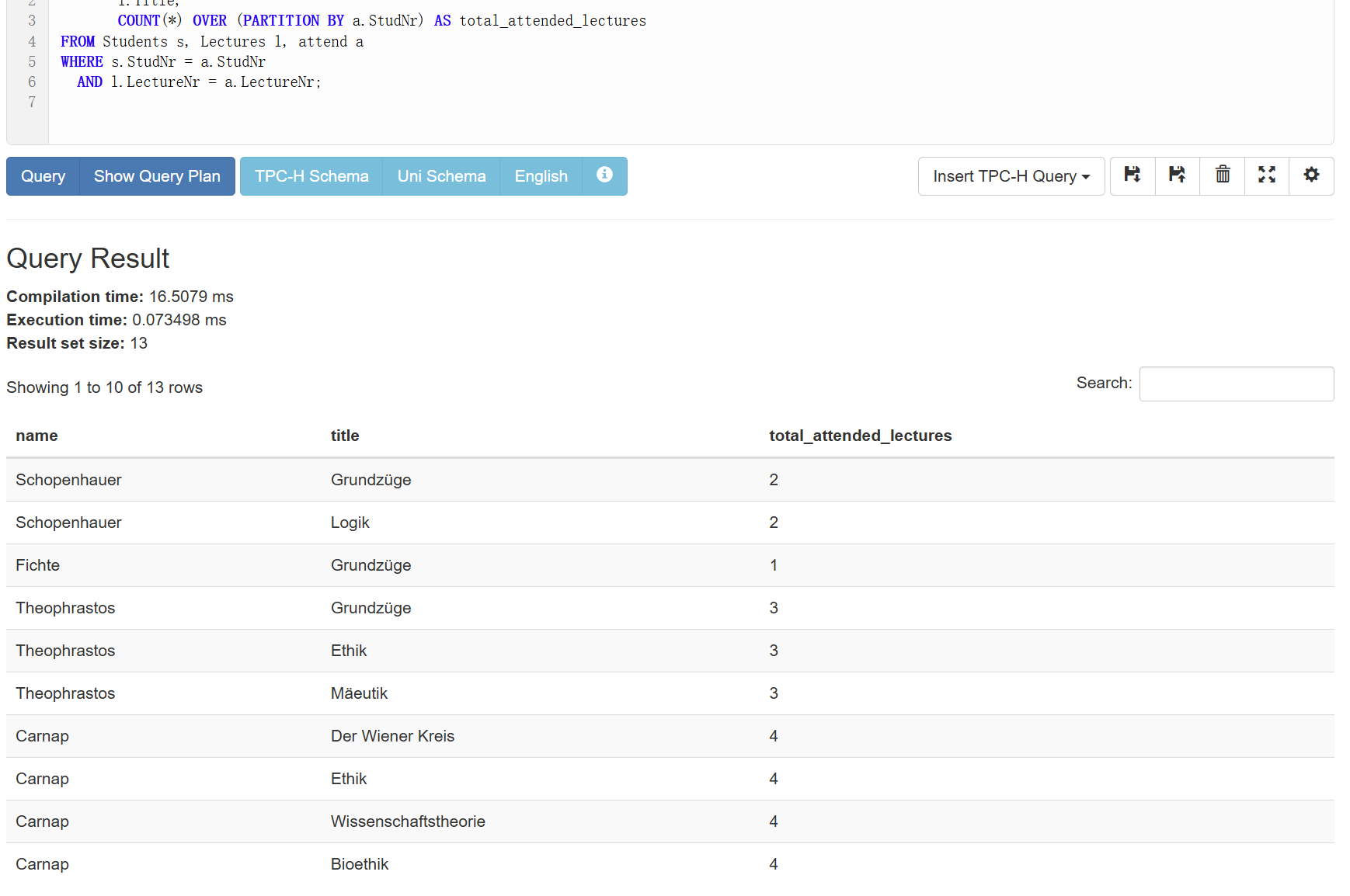
或者
1 | SELECT s.name, |
也是一样的效果。
例子2:假如我们现在只关注现有的test表,想知道每个学生的排名:
1 | SELECT s.name, t.Grade, rank()OVER ( ORDER BY t.Grade ASC) |
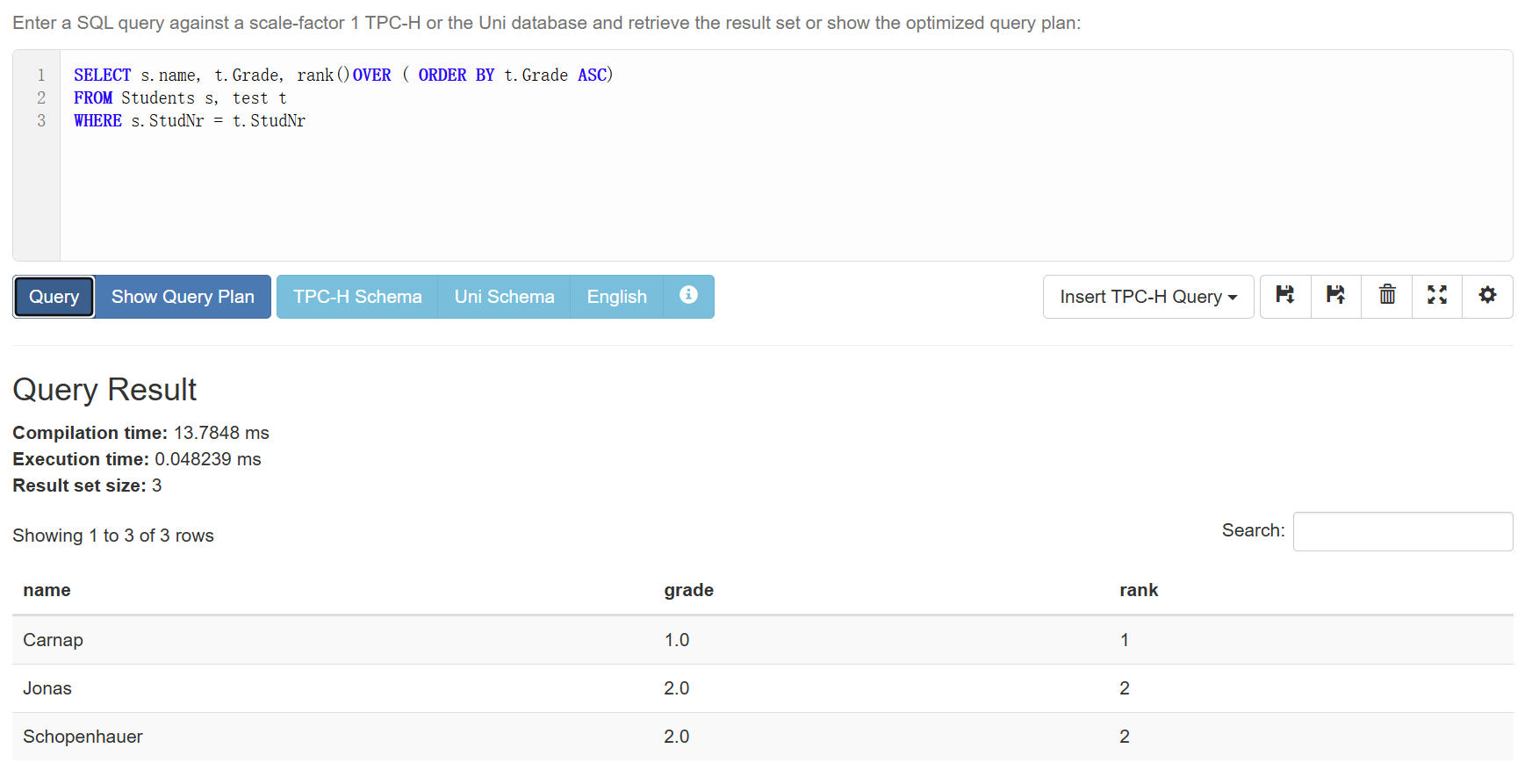
这里的rank会自动实现跳号的功能,即如果A,B的值为1,C的值为2,那么A,B的排名都是1,C的排名会自动变成3,而不是2。
常用的窗口函数
1)排名类:
用来给每行一个名次/序号。
ROW_NUMBER():每行一个唯一序号(不管并列)(1,2,3,4…)RANK():并列同名次,会跳号(1,1,3…)DENSE_RANK():并列同名次,不跳号(1,1,2…)PERCENT_RANK():把排名映射到 0~1(相对排名)CUME_DIST():累计分布(<= 当前行的比例)NTILE(n):分桶,把排序后的行分成 n 份(比如分成 4 桶做四分位)
2)聚合类(在GROUP BY里用的聚合函数也可以用在窗口上):
SUM(...) OVER (...):组内总和 / 累计和AVG(...) OVER (...):组内平均 / 滑动平均COUNT(...) OVER (...):组内计数 / 累计计数MIN/MAX(...) OVER (...):组内最小/最大(也可做滚动最小/最大)
3)取相邻对象(分析趋势、做差分)
LAG(x, k, default):往前第 k 行的 x(默认 k=1)LEAD(x, k, default):往后第 k 行的 xFIRST_VALUE(x):窗口内第一行的 xLAST_VALUE(x):窗口内最后一行的 xNTH_VALUE(x, n):窗口内第 n 行的 x(不是所有库都有)
递归/Recursion
递归的基本框架:
1 | WITH RECURSIVE 名字(列...) AS ( |
SQL里递归的写法和Induction/Iteration一样。先定义base case,再一层一层递进。
或者说是先给出起始集合,再反复应用递推规则,不断扩张结果集合,直到没有新东西为止。
而不是像其他编程语言里一样一直调用自己,直到碰到base case,然后停止。
在此基础上我们还可以通过定义一列新的内容(次数,长度等)以及增加基于这列信息的判断条件,来实现控制循环次数(上限)。(见例子3)
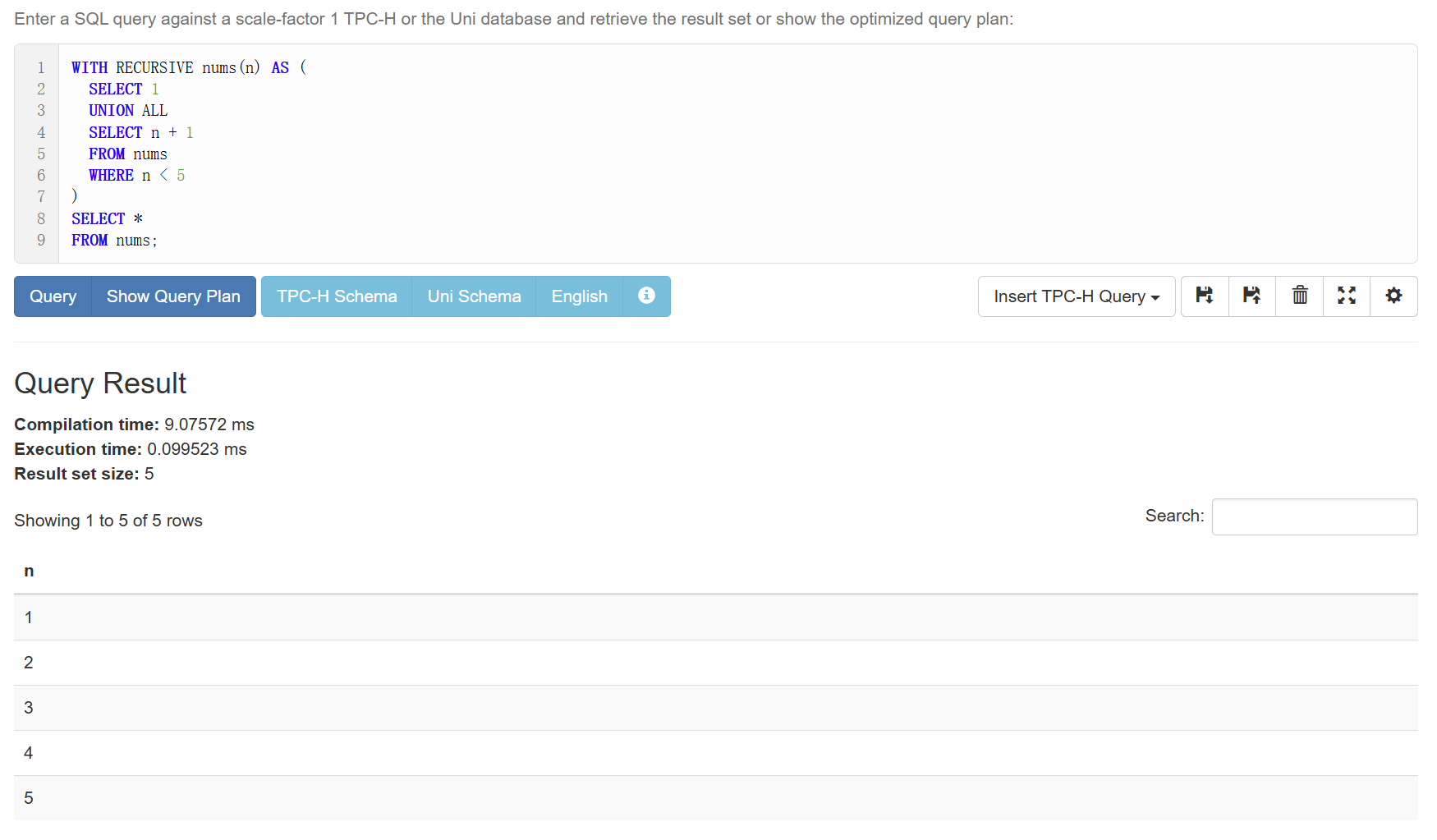
例子1
生成1-5
1 | WITH RECURSIVE nums(n) AS ( |
例子2
假设我们现在希望查询“Der Wiener Kreis”(LectureNr=5259) 这门课的的所有前置课程(包括直接和间接)。
普通的查找直接前置课程:
1 | SELECT Title |
查询第n轮前置就是:
1 | select v1.Predecessor |
我们把这个完整查询拆成2步:
利用递归创建子查询(临时表),在原来require表的基础上添加所有间接前置课程
1
2
3
4
5
6
7
8
9
10
11
12
13
14WITH RECURSIVE TransPrereq (Prereq, Successor) AS (
-- 递归的基础查询
SELECT Predecessor, Successor
FROM require
UNION ALL
-- 递归部分 (Prereq -> ... -> Successor)
SELECT t.Prereq, r.Successor
FROM TransPrereq t, require r
WHERE t.Successor = r.Predecessor
)
SELECT *
FROM TransPrereq每次递归时相当于有这样一个链:
1
t.Prereq -> t.Successor = r.Predecessor -> r.Successor
我们将一头一尾加进结果里。
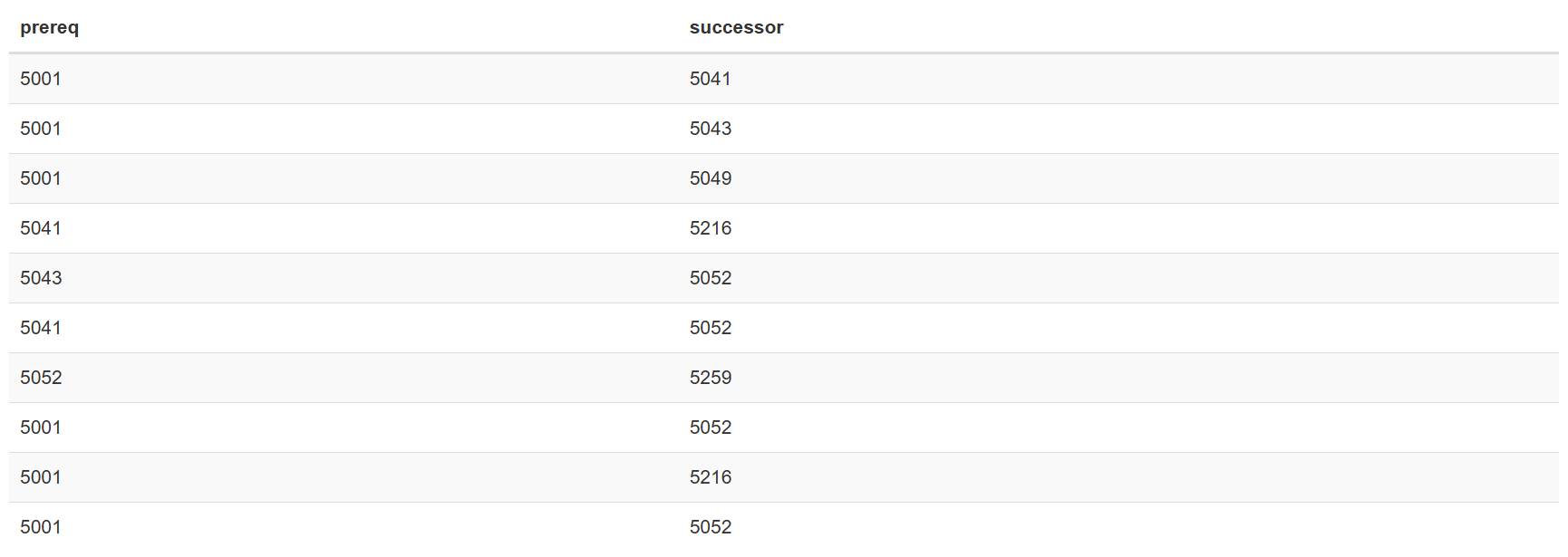
在里面找’Der Wiener Kreis’的所有前置课程
合并起来:
1 | WITH RECURSIVE TransPrereq (Prereq, Successor) AS ( |
例子3
考虑下面这个图:
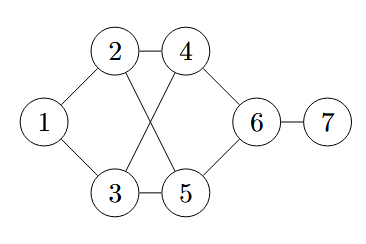
用SQL表示是这样的:
1 | WITH recursive singleDirection (a ,b ) as ( |
如果我们现在想判断从1出发是否能到6,我们就可以这样:
- 利用递归生成一张查询结果表,列出所有可到达的pair
- 然后找(1,6)是否在里面
1 | WITH recursive singleDirection (a ,b ) as ( |
为了避免无穷展开,我们现在加个限制:图的直径为4,即不考虑长度超过4的路径,那么就可以加一列来记录路径长度并且限制长度:
1 | WITH recursive singleDirection (a , b) as ( |
PostgreSQL
pgvector
pgvector是PostgreSQL的一个拓展,用于直接做向量存储与相似检索。
定义向量列
比如说定义10维的vector列:
1 | CREATE TABLE items ( |
(embedding只是列名)
插入向量
1 | INSERT INTO items (embedding) |
查看向量维度
1 | SELECT embedding.dim |
运算符与距离度量
| 运算符 | 含义 |
|---|---|
<-> |
L2(欧氏距离) |
<#> |
negative inner product(负内积) |
<=> |
cosine distance(余弦距离) |
<+> |
L1(曼哈顿距离) |
<~> |
Hamming distance(二值向量) |
<%> |
Jaccard distance(二值向量) |
例子:计算距离并输出一个dist列
1 | SELECT |
会计算embedding列的所有vector到[1,2,3,4,5,6,7,8,9,10]的L2距离,然后按照或者距离进行排序。(注意,ORDER BY默认是升序)
例子2:找某条记录的近邻
1 | SELECT id |
例子3:给每个找近邻
假设有一个表wiki(word TEXT, embedding vector(50))。
1 | SELECT w1.word, w2.word |
CROSS JOIN:笛卡尔连接(不写 ON 条件)LATERAL (subquery):这个 subquery 会根据当前w1变化而变化
所以对外层每一行 w1,运行一次括号里的子查询,得到若干行结果,然后把这些结果行和当前 w1 拼在一起输出。